
🐳OpenAI’s o1 Faces Competition: Meet DeepSeek-R1-Lite, Moonshot's k0-math, and Alibaba's Marco-o1
Weekly China AI News from November 18, 2024 to November 24, 2024

Hi, this is Tony! Welcome to this week’s issue of Recode China AI, a newsletter for China’s trending AI news and papers.
In this issue, I will discuss three large reasoning models developed by Chinese AI labs and companies. They are seen as challengers to OpenAI’s o1, which can solve complex problems by reasoning more deeply and thoroughly before responding.
While these models have yet to surpass o1 in terms of benchmark performance, their release shows that the advanced “inference compute” paradigm pioneered by o1 is not exclusive to OpenAI. More companies, including those in China, are capable of replicating and potentially leveraging this technology.
DeepSeek-R1-Lite-Preview
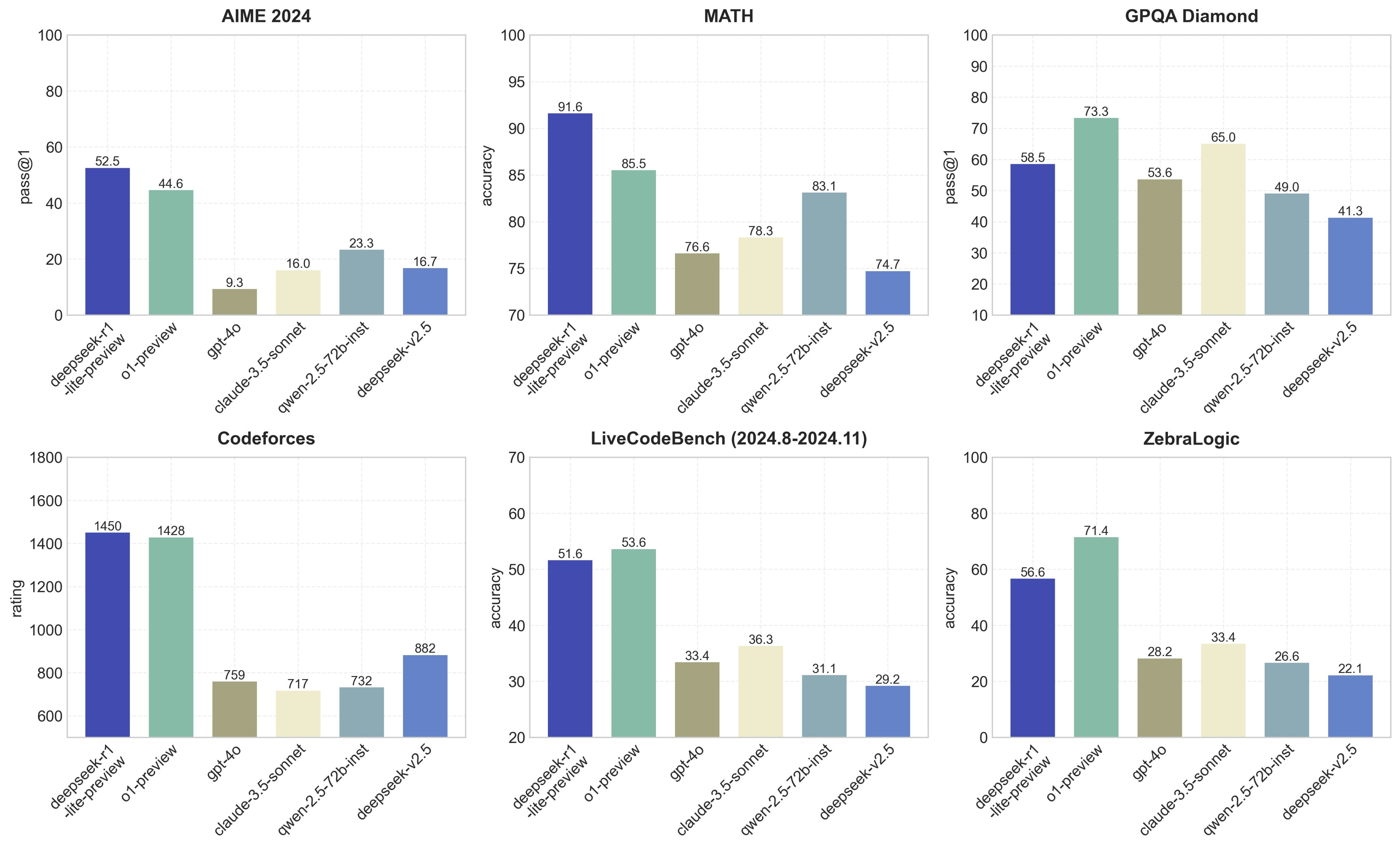
What’s New: Last week, DeepSeek introduced its equivalent of OpenAI’s o1, DeepSeek-R1-Lite-Preview, a model designed to improve reasoning by increasing inference time.
Backed by High-Flyer Capital Management, a Chinese quantitative hedge fund giant, DeepSeek claims its R1-Lite-Preview outperforms OpenAI’s o1-preview-level performance on two major benchmarks: AIME (American Invitational Mathematics Examination) and MATH. These benchmarks are rigorous tests of mathematical ability, commonly used in competitive or academic settings.
You can try DeepSeek-R1 yourself at chat.deepseek.com. It currently limits users to 50 queries per day.
How It Works: Much like OpenAI’s o1, DeepSeek-R1 tackles complex problems with a step-by-step thought process. It plans, analyzes, sometimes backtracks, and fact-checks its reasoning before providing an answer. On benchmarks like AIME, the model has shown improved accuracy as the length of its reasoning increases.
While the technical paper of DeepSeek-R1 is not publicly available yet, according to DeepSeek, the R1 series is trained using reinforcement learning, with a focus on reflection and verification during its reasoning process. The current Lite-Preview version is built on a smaller base model and hasn’t yet unlocked the full potential of its long reasoning chains.
First Impression: DeepSeek-R1-Lite-Preview stands out by sharing its thought process, unlike OpenAI’s o1 that keeps its reasoning hidden. This transparency makes interacting with the model both insightful and fun.
For example, when I asked the model to count the number of “1”s in a binary sequence, it walked me through its thought process in real-time:
I should probably start by just looking at the sequence carefully and counting each '1' one by one.
Wait a minute, that seems like a lot of ones. Let me double-check. Maybe I miscounted somewhere. Let's try again, more slowly.
This is getting confusing. Maybe I should just stick with counting the ones directly.
Wait, now I have thirteen ones. Earlier I had fourteen and then twelve. This is not consistent. I must be making a mistake somewhere. (🤣🤣🤣)


DeepSeek-R1 has already impressed the tech community at least. A biomedical scientist praised the model as being at a PhD-level, and said its reasoning as far superior to the o1-preview. A Menlo Ventures VC tested the model on one of the hardest problems from the International Math Olympiad. It took 262 seconds to solve, yet failed.

But some critics believe the release of R1 may have been rushed, citing areas for improvement in both its accuracy and reasoning speed. And like OpenAI’s o1, DeepSeek-R1 also struggles with simple logic puzzles like tic-tac-toe.
Still, as DeepSeek plans to open-source the model and release an API, DeepSeek-R1 already stands as a victory for the open-source community.
k0-math

What’s New: k0-math is a new mathematical reasoning model developed by Moonshot, a Chinese AI startup backed by Alibaba and Tencent with a valuation of over $3 billion.
The company claimed that k0-math has surpassed OpenAI’s o1 series models, including o1-mini and o1-preview, in tests such as the high school entrance exam, college entrance exam, postgraduate entrance exam, and MATH. It still trails o1-mini in OMNI-MATH and AIME benchmark tests.
You can try k0-math yourself at kimi.moonshot.cn in Kimi-Math.
How It Works: The model uses reinforcement learning and chain-of-thought reasoning to simulate human-like thinking and reflection processes. This approach enhances its capability to tackle complex mathematical problems by spending more time on reasoning and planning strategies.
However, the current version of k0-Math faces challenges with geometric problems that are difficult to describe using LaTeX. It also tends to overthink overly simple math problems. Additionally, the model currently supports only single-round interactions, and multi-round follow-ups may not be well-optimized yet.
Marco-o1

What’s New: Marco-o1, developed by Alibaba’s international division, is an AI reasoning model designed for open-ended problem-solving tasks where traditional clear standards and quantifiable rewards are absent.
How It Works: Unlike o1 or R1 models that rely on reinforcement learning and extended inference times to solve complex problems, Marco-o1 focuses on addressing open-ended challenges through innovative reasoning techniques.
The model integrates Chain-of-Thought (CoT) fine-tuning, Monte Carlo Tree Search (MCTS), and a self-reflection mechanism to enhance its reasoning capabilities. Fine-tuning is performed using a combination of open-source CoT datasets and synthetic data created by the AIDC-AI team.
By leveraging MCTS (Marco-o1-MCTS), the model uses output confidence scores to guide searches, expand its solution space, and improve decision-making accuracy. The addition of a self-reflection mechanism enables the model to critique and refine its own reasoning, leading to significant performance gains on challenging tasks.
Researchers have also extended Marco-o1’s capabilities to machine translation.
It’s worth noting that the model is not associated with Alibaba’s Qwen research team, which is likely working on developing its own o1-style model.
Previous posts also introduced an experimental project from Shanghai Jiao Tong University that document their journey to replicate OpenAI's o1 model.
🍓Replication Through Exploration: The Journey to Understanding OpenAI's o1

What’s New: When OpenAI unveiled its reasoning model, o1, capable of tackling complex math and coding problems, it sparked intense curiosity across the global AI community. Researchers everywhere are eager to uncover the secrets behind o1’s remarkable capabilities, despite the scarcity of technical details provided by OpenAI.
Starting in April 2024, Baidu’s ERNIE Bot included the ERNIE 4.0 Tool version, which leverages “slow thinking” to enhance reasoning with thought processes and reflection, inspired by human dual-process thinking.

Weekly News Roundup

Huawei plans to begin mass production of its latest AI chip, the Ascend 910C, in early 2025, despite facing significant challenges due to U.S. trade restrictions. These restrictions have impacted Huawei’s ability to achieve the high yields necessary for commercial success, as the chip's production yield is currently only about 20% due to the lack of advanced lithography tools. (Reuters)
Chinese AR start-up Rokid has unveiled its latest product, the Rokid Glasses, which integrate Alibaba’s AI technology to compete with Meta in the smart glasses market. The new glasses, priced at 2,499 yuan (US$345), are equipped with LLMs from Alibaba's Tongyi Qianwen family. (SCMP)
China has established a new AI Experts Committee to shape global AI development and governance. The committee was announced during the World Internet Conference held in Zhejiang province. Wang Jian, founder of Alibaba Cloud, has been appointed as the chief expert. (SCMP)
Stanford University has released a new AI index ranking that shows the United States leading global AI innovation, easily surpassing China. The report measures the "vibrancy" of the AI industry across multiple dimensions, including research, investment, and responsible technology development. While ranking second, China has shown significant growth, including most generative AI patents globally, strong university research publications, and notable AI models like Baidu’s ERNIE. (Associated Press)
Uber is reportedly in talks to invest over $10 million in the U.S. IPO of Pony.ai, a Chinese autonomous driving startup. This investment comes as Pony.ai plans to issue 20 million American depository shares on Nasdaq, aiming to raise approximately $260 million. (Bloomberg)