
🍓Replication Through Exploration: The Journey to Understanding OpenAI's o1
A team from Shanghai Jiao Tong University, New York University, and others document their journey to replicate OpenAI's o1 model, introducing a novel concept called "Journey Learning".

What’s New: When OpenAI unveiled its reasoning model, o1, capable of tackling complex math and coding problems, it sparked intense curiosity across the global AI community. Researchers everywhere are eager to uncover the secrets behind o1’s remarkable capabilities, despite the scarcity of technical details provided by OpenAI.
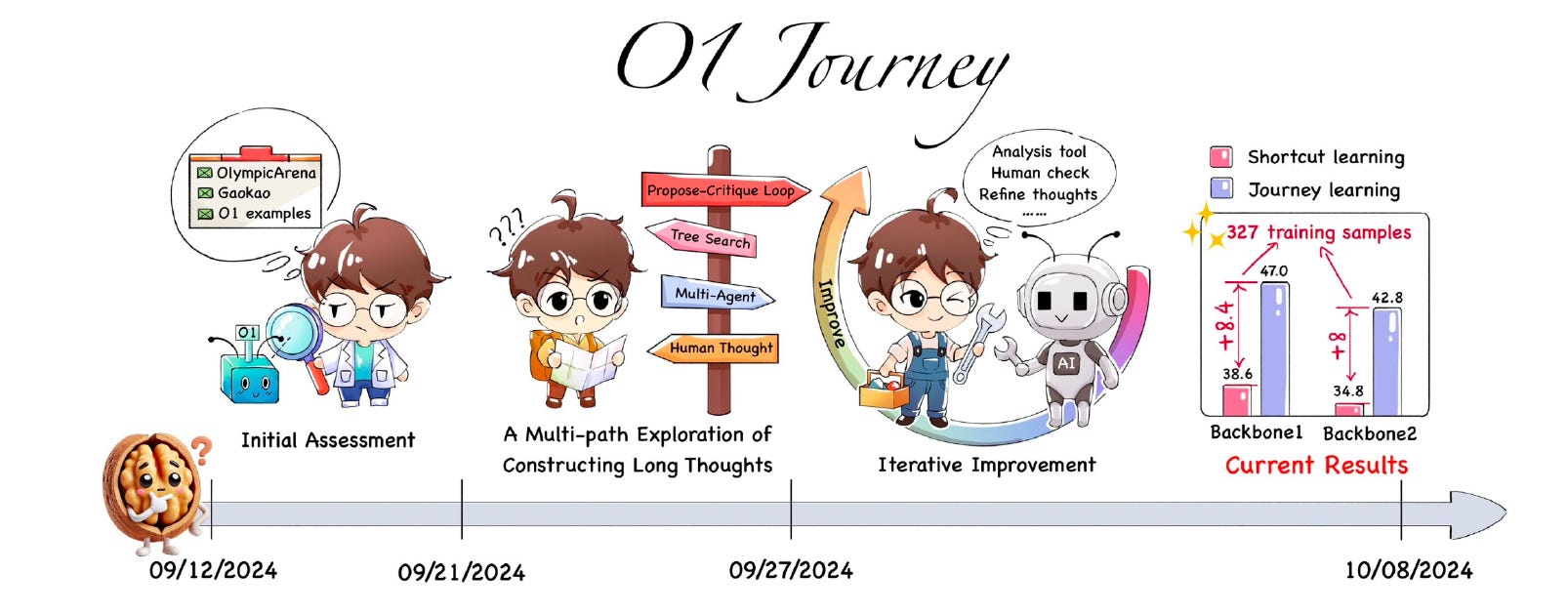
Lately, a team of researchers from Shanghai Jiao Tong University, New York University, and others attempted to replicate the capabilities of o1. Their technical report, O1 Replication Journey: A Strategic Progress Report – Part 1, chronicled each step of their replication efforts - both successes and failures.
The team introduced a novel “journey learning” paradigm, contrasting it with traditional “shortcut learning” methods. Journey learning emphasizes the entire exploration process, including trials, errors, reflections, and corrections, mirroring human cognitive processes.
What is Shortcut Learning? Shortcut learning is a traditional paradigm of machine learning that can be effective for specific, well-defined tasks but struggles with complex, dynamic, and open-ended problems. Imagine you’re preparing for a history exam: instead of studying events, people, and causes, you simply memorize a list of dates and names. You might do well on the test, but you wouldn’t truly understand history. This approach is akin to shortcut learning in AI - where achieving specific metrics often takes precedence over a deep understanding.
Shortcut learning focuses on performance metrics or completing tasks quickly, often by expanding training data rather than improving learning algorithms. However, these systems falter when dealing with situations outside their training data and usually lack the ability to recognize and correct their errors.
What is Journey Learning? Journey learning is a new paradigm for AI development, proposed as a response to the limitations of shortcut learning. It emphasizes learning and exploration rather than merely achieving quick results or relying on massive datasets. The authors believe journey learning was crucial to o1's success, and they are attempting to replicate this approach.
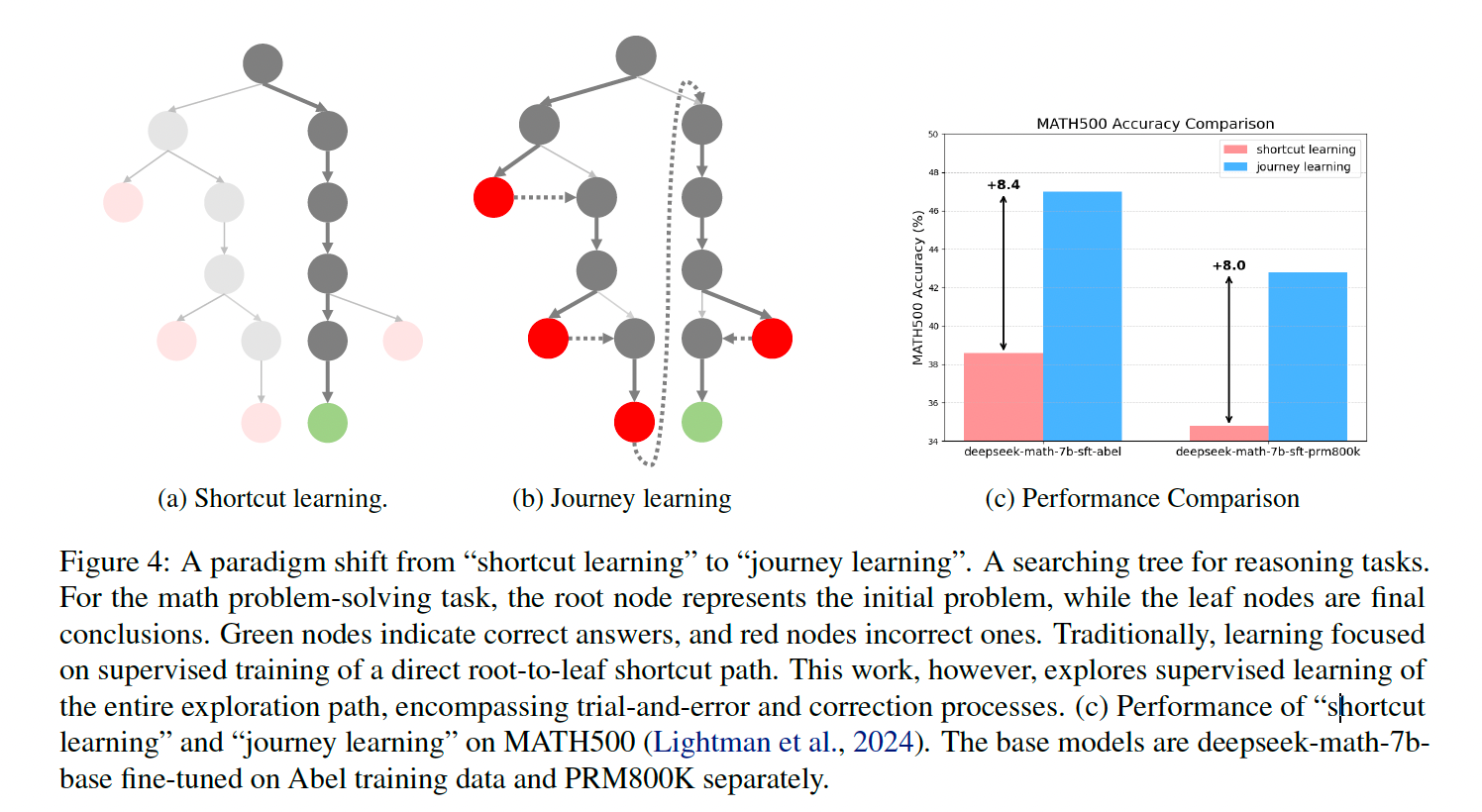
Unlike traditional shortcut learning, journey learning allows the model to explore the entire decision trajectory, mimicking human problem-solving processes.
With 327 training samples, journey learning outperformed conventional supervised learning methods by over 8% on the MATH dataset.
o1’s Thought Process: Through meticulous analysis of o1’s outputs, the team identifies key characteristics of its thought process:
Iterative Problem-Solving: o1 breaks down complex problems into smaller components and gradually explores related expressions.
Key Thought Indicators: The use of specific keywords like “Therefore”, “Alternatively”, “Wait”, and “Let me compute” reveals different stages of o1’s reasoning process.
Recursive and Reflective Approach: O1 frequently re-evaluates and verifies its intermediate results.
Exploration of Hypotheses: O1 demonstrates flexibility by testing different hypotheses and adjusting its approach based on new information.
Conclusion and Verification: O1 emphasizes validating conclusions before finishing a problem.
Replication of o1: The authors outlined various attempts to construct “long thoughts” - sequences of reasoning steps that capture the trial-and-error nature of human problem-solving. These attempts include:
Tree Search Algorithms with process-level reward models to guide exploration and backtracking.
Propose-Critique Loop, where an agent proposes reasoning steps, and another critiques and suggests corrections.
Multi-agent Debate Systems for collaborative reasoning and integration of diverse perspectives.
Complete Human Thought Process Annotation, meticulously documenting human problem-solving steps.
Two key components of o1 replication are the On-Policy Reasoning Tree—a tree-like structure where each node represents a problem-solving step—and a Reward Model, which assesses the quality of reasoning steps.
The team used a fine-tuned version of the DeepSeekMath-7B-Base model as their policy model to build the reasoning tree. They experimented with different reward models, including math-shepherd and o1-mini, and found that o1-mini is more effective at evaluating reasoning steps. They used beam search, guided by the reward model, to prune the reasoning tree and make the search more efficient. For evaluation, the team utilized a visual data analysis platform built using Streamlit for intuitive evaluation of model performance.
To train their models, the authors also used DeepSeekMath-7B-Base as their pre-trained language model. The training process involved Supervised Fine-Tuning (SFT) by fine-tuning the model on datasets with clear step-by-step solutions, and Direct Preference Learning (DPO) that trains the model to learn by comparing correct and incorrect responses.
The results indicated that models trained with journey learning showed improvement over those trained with shortcut learning. Specifically, journey learning led to improvements of +8.4% and +8.0% on the benchmark dataset. However, the improvements from DPO were less substantial. The authors acknowledged that this was an initial exploration and plan to further investigate preference learning and reinforcement learning in the future.
Why It Matters: AI research, especially at the level of models like o1, is often criticized for being too insular. Long projects, little interim sharing, and only publishing “big results” can leave the broader research community playing catch-up.
This research team is challenging that approach by providing real-time updates, explaining every phase—from initial assessment to deep dives into complex reasoning pathways.
Our primary goal is not to achieve performance parity with OpenAI’s O1 - a task we acknowledge as extremely challenging given the limited information and resources available. Instead, our mission is to transparently document and share our exploration process, focusing on the fundamental questions we encounter, uncovering new scientific questions, and sharing our trial-and-error experiences with the broader AI community. By doing so, we aim to reduce the total collective cost of trial-and-error in the world and identify the key factors contributing to O1’s reported success.
The journey is far from over. The team plans to continue iterating on o1 replication and journey learning, sharing their tools and insights publicly. Their work could lay the groundwork for future AI models to better emulate human-like reasoning, inspiring more collaborative and transparent research in the field.
