
🧐Inside DeepSeek-V3: Are Export Controls Falling Short?
Weekly China AI News from December 30, 2025 to January 5, 2025

Hi, this is Tony! Welcome to this week’s issue of Recode China AI, a newsletter for China’s trending AI news and papers.
I should have written a review of DeepSeek-V3 sooner, given all the buzz it has generated. In this post, I discussed why the model is so cost-effective, who DeepSeek and its team are, and whether U.S. export controls on China are falling short.
What’s New: Meet DeepSeek-V3

DeepSeek, an AI lab backed by High-Flyer, a quantitative hedge fund in China, released its open-source large language model (LLM), DeepSeek-V3, in late December.
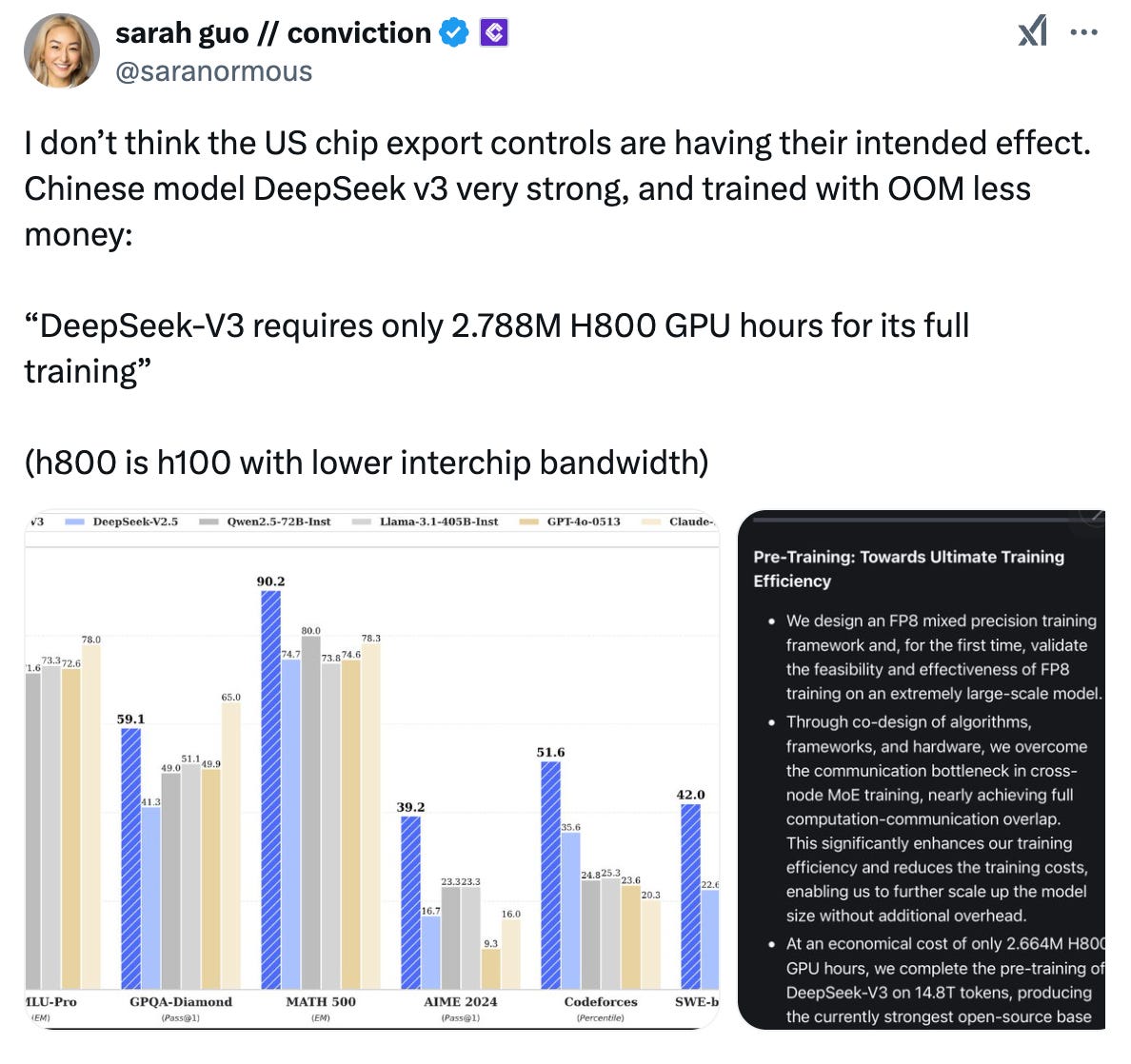
The model immediately garnered attention for two key reasons. First, it outperformed other SOTA open LLMs like Qwen2.5-72B and Llama-3.1-405B across benchmarks while competing closely with proprietary models such as GPT-4o and Claude 3.5 Sonnet. Second, the model with 671 billion parameters achieved these results while using only 2.788 million GPU hours for training, costing under $6 million. In comparison, Meta’s Llama 3.1 405B, with fewer parameters than DeepSeek-V3, used about 30.84 million GPU hours – about 11 times the compute used by DeepSeek-V3.

DeepSeek-V3’s inference costs are also lower compared to other SOTA models, with $0.27 per million input tokens (for cache misses), $0.07 (for cache hits), and $1.10 for output tokens. In contrast, Claude 3.5 Sonnet’s pricing is $3 per million input tokens, and $15 per million output tokens.

DeepSeek-V3 came despite limited access to advanced GPUs due to U.S. export controls, which raised a crucial question: Are export controls working as intended to slow China’s AI progress?
Why is DeepSeek-V3 So Cheap?
There are already many detailed analysis of DeepSeek-V3’s architectural innovations. If you are really interested in technical details, take a look at Zvi Mowshowitz’s review of the model.
In my view, the cost efficiency of DeepSeek-V3 stems from the following techniques:
Highly sparse MoE Architecture: Although the model has 671 billion parameters, only 37 billion are active during inference (about 5.5% of the model’s capacity). This sparsity reduces computational costs but also complicates training. Training MoE models involves dynamically routing inputs to specific experts, which can lead to challenges like load imbalance (some experts being overused) or instability in gating.
Multi-Head Latent Attention (MLA): MLA is an architectural technique first introduced in the paper of DeepSeek-V2. It optimizes memory efficiency in inference by “compressing the Key-Value (KV) cache into a latent vector” while maintaining performance. MLA reportedly can reduce memory usage to 5%-13% of the Multi-Head Attention (MHA) architecture. While MLA is less common than Grouped Query Attention (GQA) – widely used in models like LLaMA-2 and Mistral7B – it could receive more interests along with DeepSeek’s growing influence.

FP8 Mixed-Precision Training: LLM training typically uses FP32 full-precision or FP16/BF16 mixed-precision, but a 2023 Microsoft paper proposed FP8 for LLM training, reducing memory usage by 39% and running 75% faster than BF16. The DeepSeek-V3 paper reported similar results, with FP8 theoretically doubling the computational speed compared with BF16.
Auxiliary-Loss-Free Load Balancing: This technique ensures computational loads are evenly distributed among experts without compromising performance. It is also elaborated in an ICLR 2025 submission paper if you want to know more details.
Other methods include Multi-Token Prediction (MTP) training – first proposed by Meta in 2024 – which densifies training signals and enhances data efficiency. DeepSeek also used their DeepSeek-R1 reasoning model for synthetic fine-tuning data. Training was remarkably smooth, with no rollbacks or outages.
DeepSeek-V3 still needs much improvement. For example, when asked “what model are you” without a question mark, the model would say it’s ChatGPT. The reasons are still unknown. The model was likely trained on datasets containing a significant amount of ChatGPT-generated text. Or DeepSeek may have used API calls to generate training data from ChatGPT. In addition, its performance on AidanBench, which evaluates response diversity, lags behind leading models.

Who is DeepSeek?
 Is Closing The Gap With OpenAi - 9meters")
I bet you won’t find much information about this “secret” AI lab. Founded in April 2023, DeepSeek is backed by High-Flyer Capital Management – one of the largest Chinese quantitative hedge fund managing around RMB 60 billion ($8 billion). Instead of raising funds as quickly as possible or building commercial applications, it focuses on developing foundational AI technologies and open-sourcing all its models. DeepSeek’s CEO, Liang Wenfeng, who also founded High-Flyer, is so low-key that I couldn’t even find a clear image. The one you might find on Google is actually from another person with the same name in the furniture industry. The company’s mission is “Unraveling the mystery of AGI with curiosity.”

Here are two articles I recommend if you’re interested in learning more. The first one is from Financial Times’ The Chinese quant fund-turned-AI pioneer. The second one is ChinaTalk’s translation of Liang’s interview.

The team behind DeepSeek-V3 raised public interest. Lei Jun, the Co-founder and CEO of Xiaomi, reportedly offered tens of millions of RMB to recruit a DeepSeek researcher named Luo Fuli.
A Chinese media outlet reported that the team primarily consists of recent graduates and doctoral candidates, mostly from universities like Tsinghua and Peking University. For instance:
Gao Huazuo, a PekingU physics alum, and Zeng Wangding, a Beijing University of Posts and Telecommunications grad student, developed the MLA architecture.
Shao Zhihong, a CoAI lab doctoral student from Tsinghua, contributed to GRPO (Group Relative Policy Optimization) and other projects like DeepSeek-Prover and DeepSeek-Coder.
Zhao Chenggang, a Tsinghua engineer with supercomputing expertise, plays a crucial role in infrastructure development.
DeepSeek’s team also blends algorithmic innovation with hardware optimization. Last year, the lab deployed Fire-Flyer 2, equipped with 10,000 PCIe A100 GPUs, delivering performance comparable to the DGX-A100 while cutting costs by half and reducing energy consumption by 40%.
Building LLM on a Tight Budget and Limited Hardware

Training models at lower costs while maintaining or improving performance is common. For instance, Hugging Face’s DistilBERT reduced Google’s BERT model size by 40% while retaining 97% of its performance on downstream tasks. Similarly, Google’s GLaM, with 1.2 trillion parameters – seven times more than GPT-3’s 175 billion – activates only about 97 billion parameters per token prediction. This design allowed GLaM to use just one-third of the energy required for GPT-3 and half the computational power during inference.
So why is DeepSeek-V3 generating so much buzz? In addition to its architectural innovations, perhaps most notably, it’s developed by a Chinese AI lab, which cannot access the most advanced GPU. “DeepSeek’s issue isn’t a lack of money; it’s the restrictions on high-end chips,” said Liang in an interview.
The DeepSeek-V3 technical report explicitly said in the abstract that the model required just 2.788 million H800 GPU hours for full training.
The H800 GPU, a modified version of Nvidia’s flagship H100, is designed for the Chinese market due to U.S. export controls starting October 2022. H800 features reduced interconnect bandwidth (400 GBps vs. H100’s 900 GBps). Until October 2023, the H800 was the best GPU available to Chinese customers, though more recent export controls have limited access to even these, leaving Chinese companies with the less capable H20 models. According to the Financial Times, ByteDance and Tencent each ordered around 230,000 Nvidia chips, including the H20, last year.

These export controls, citing national security concerns, aim to curb China’s access to advanced AI chips, potentially slowing its ability to develop and deploy cutting-edge AI models for military applications. However, most Chinese AI development remains focused on civilian and commercial uses, such as e-commerce and social media.
Faced with hardware restrictions, Chinese AI labs like DeepSeek are forced to innovate in algorithms, architectures, and training strategies. A researcher estimated that DeepSeek improved the usage efficiency of H800 by 60% in six months. For DeepSeek-V3, the value reached 196, as 37 billion parameters × 14.8 trillion tokens ÷ 2.788 million GPU hours. In comparison, DeepSeek-V2 had a value of 121, calculated as 21 billion parameters ÷ 0.1728 million GPU hours (per 1 trillion tokens). DeepSeek-V3’s Model FLOPs Utilization (MFU) is estimated at 39.0% for 4K context length pre-training.
DeepSeek-V3 is a great example of a principle shared by Alexandr Wang of Scale AI: “Improving on any one of the three pillars of AI (compute, data and algorithms) improves the technology as a whole.”
DeepSeek isn’t alone. Lee Kai-fu, a renowned computer scientist and founder of 01.AI, discussed a similar method in an August 2024 Wall Street Journal interview: “We don’t have a lot of GPUs, so we focus on building highly efficient AI infrastructure and inference engines.” 01.AI used this mindset to train Yi-Lightning, a model that reportedly rivals GPT-4o but cost only $3 million to develop.
Are Export Controls Failing
The creation of DeepSeek-V3 also sparked a critical question: Are export controls failing? The model surprised many on X and Reddit, as they had expected these measures to halt China’s progress in developing advanced models.
Kevin Xu from Interconnect summed it up well in a tweet:
Both AI progress and export control policies have "benefited" from squishy definitions. what is frontier? what is AGI? Intentional vagueness can be quite useful.
Why do I say export control is working as intended and DeepSeek V3 is evidence?
1. DeepSeek is not frontier. It is very good, but not frontier. o3, Sonnet, Gemini are frontier. DeepSeek V3's big contribution is frontier-ish performance done on a fraction of the cost and it's all open, so you can verify, use, improve on your own (in an alternate universe w/o export control, DeepSeek would've achieved frontier status by now)
2. Export control's intended goals are a) blunt China's technical progress, especially AI; b) even if China keeps pushing ahead, they can't do that using our best technology (and our allies'). Both are largely happening today, and will continue if export control stays where it is today while Blackwell floods the market in volume (I hope incoming Trump team understands this trajectory).
So yes, export control policies are working for the most part as intended. Are they perfectly implemented? nope! Are there loopholes? Oh plenty! Is the intention even the strategically correct one? That's a totally different question that should be assessed separately. But because of all the squishy definitions, reasonable people can disagree on all this.
Paul Triolo, Senior Vice President for China and Technology Policy Lead at Albright Stonebridge Group, highlighted a crucial question: the effectiveness of export controls largely depends on how their goals are defined.
Raimondo (United States Secretary of Commerce) said this year the goal was to "prevent China from training frontier models." OK, by that metric, probably not working. Others say it is about preventing China from getting to AGI first. Jury still out on this one, much more complex. We won't know for some time...
Here’s my take: Model alone doesn’t create a lasting moat. Over the past two years, other LLM developers have rapidly caught up with OpenAI. Claude-3.5-Sonnet is often considered the best model for coding. Similarly in video generations, within ten months of Sora’s release, strong competitors like Runway’s Gen-3 and Kuaishou’s Kling emerged with comparable performance. So, a Chinese company developing a GPT-4o-level model with better cost efficiency isn’t particularly surprising, even with export controls.
That said, with export controls still in place, China’s chances of surpassing the U.S. to achieve AGI first – whatever the definition – remain small. While I largely believe China will continue to keep pace with the U.S. in AI development, I don’t think any Chinese companies or labs will release a GPT-5-level model before OpenAI or Google.
“Everyone wants to pursue AGI. But aiming to be the first to achieve AGI and completely dominate others? That’s a dream we neither have nor should have,” said Lee Kai-fu in an interview.

Of course, whether Chinese companies can develop an AI super app with more users than ChatGPT is an entirely different topic.

Finally, let’s set aside export controls and US-China dynamics. I personally find it a fascinating story that a group of young, dream-driven people have come together to pursue the holy grail of AGI in China – a pragmatism-prioritized nation – and created a powerful, open-source LLM at just 1/10th the cost.
Weekly News Roundup
Alibaba Cloud reduced prices on its AI language model Qwen-VL by up to 85%. The price cuts are aimed at enticing more enterprise users to adopt Alibaba's AI offerings. (CNBC)
Alibaba Cloud partnered with Lee Kai-fu’s AI start-up 01.AI to develop advanced AI model solutions for business clients, indicating a trend towards consolidation in China's AI industry. (SCMP)
Baidu said the number of paying users for its digital library-turned-AI platform Baidu Wenku has surpassed 40 million. (MSN)
Zhipu AI unveiled GLM-Zero-Preview, its reasoning model trained with reinforcement learning. GLM-Zero excels at solving maths questions, coding, and complex reasoning tasks. The company claimed the model performs on par with OpenAI’s o1-preview in evaluations such as AIME 2024, MATH500, and LiveCodeBench.
What Sarah Guo, Scott Kennedy, and others miss is that it's the sanctions that went into effect in mid-November, less than two months ago, that should have a real effect. Previous sanctions were simply annoyances. This being said, it's quite possible DeepSeek, Alibaba, and others could copy o3's secret sauce and offer it at a much more reasonable price.
However, it's not o3 that's going to get us to level 5 AI or ASI.
Expect to see a lot of great models coming out of China this year. Next year, maybe not so much. And it's next year -- and level 5 AI and ASI -- that matters. o3 will seem like a toy in comparison.
My browser takes 500mB of RAM to play a YouTube video. It should surprise no one that China is responding to hardware restraints by picking up ready wins in software efficiency. Western/Indian coding is incredibly inefficient.
Anyway, thanks China, I don't want my oligarchs dominating the LLM space.