Last week, Cursor, Silicon Valley’s darling AI coding startup, released Composer, its first in-house coding model and agent. The company touted it as 4 times faster than competitors in their internal benchmarks, purpose-built for the editing code, reasoning across entire repositories, and handling multi-step tasks.
In a blog post, the team revealed that Composer is built on a prototype agent model called Cheetah, to understand the impact of faster agent models. “Composer is a smarter version of this model that keeps coding delightful by being fast enough for an interactive experience.”
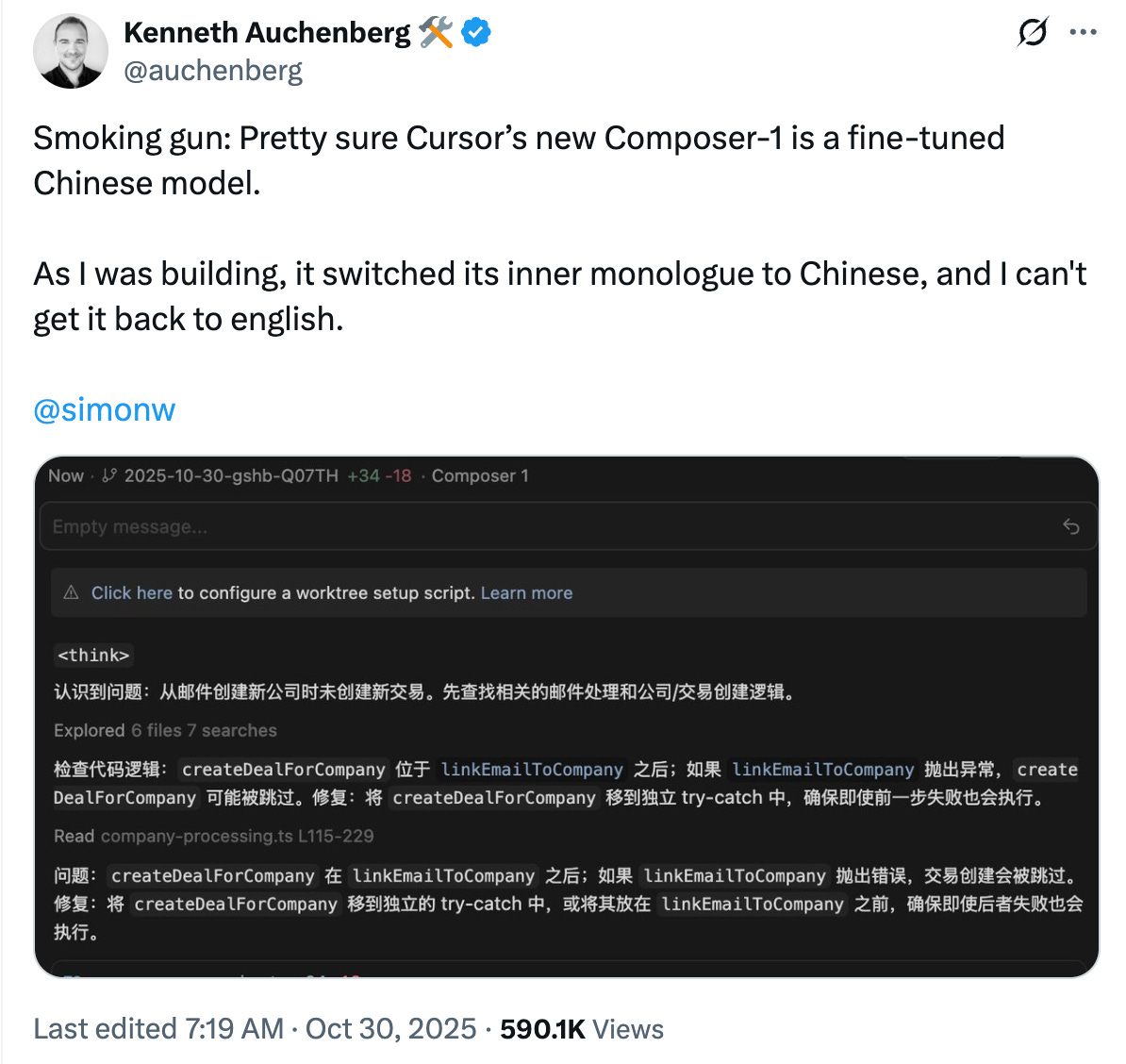
Here’s where it gets interesting. Kenneth Aucherberg, partner at Alley Corp, publicly speculated that Composer might be fine-tuned on top of an open-source LLM from a Chinese AI lab.
As I was building, it switched its inner monologue to Chinese, and I can’t get it back to English.
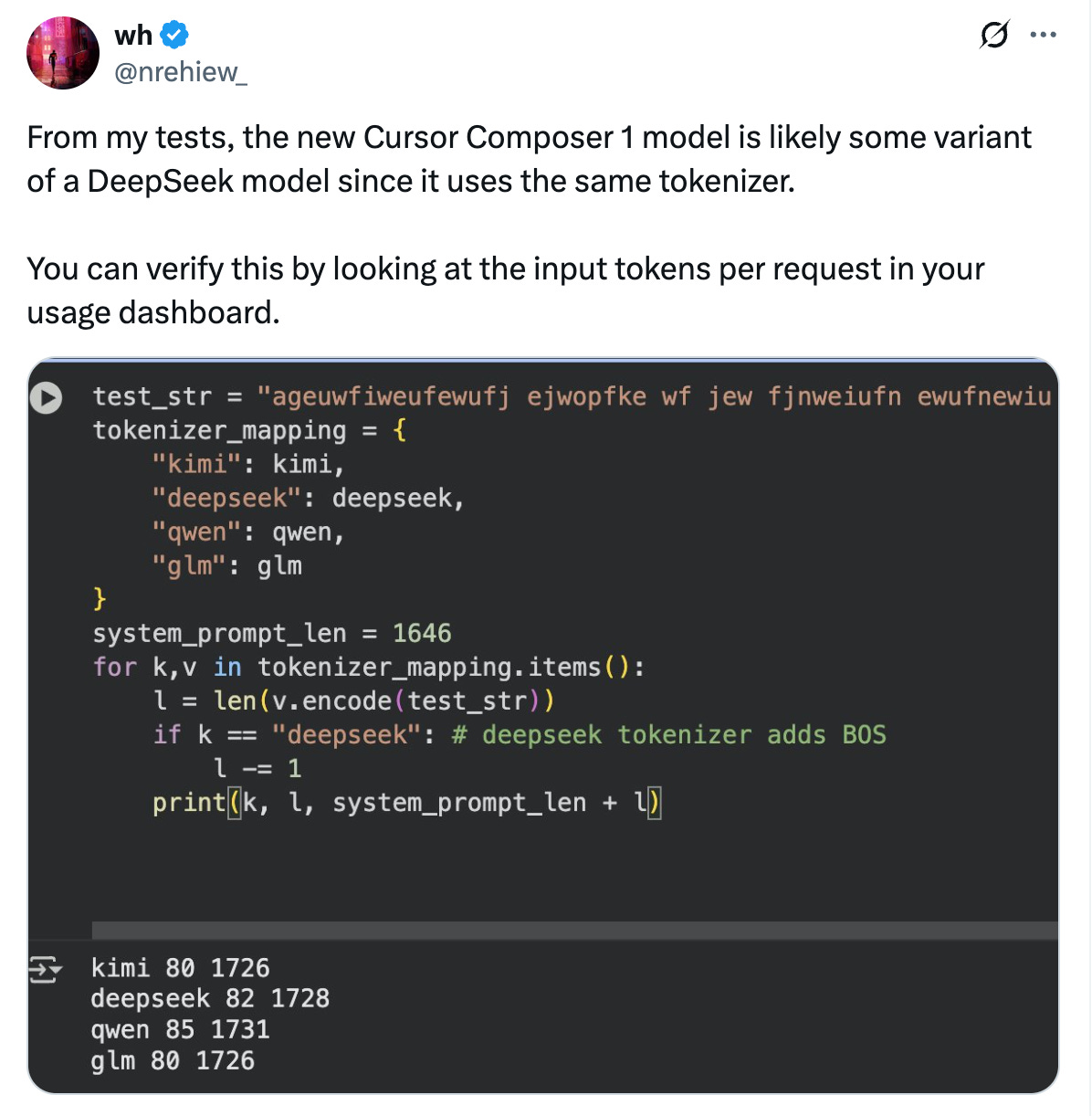
Developers in the comment section piled on with more evidences. One noted that Composer uses the same tokenizer as DeepSeek’s models.
And Cursor isn’t alone. Cognition, another billion-dollar upstart behind Devin AI coding agent, recently unveiled SWE-1.5. It’s a “frontier-size model with hundreds of billions of parameters” for software engineering tasks. Their blog post carefully mentioned selecting “a strong open-source model as the base.”
A developer reportedly jailbroke SWE-1.5 and got it to confess that it’s built on GLM from Zhipu AI (Z.ai).
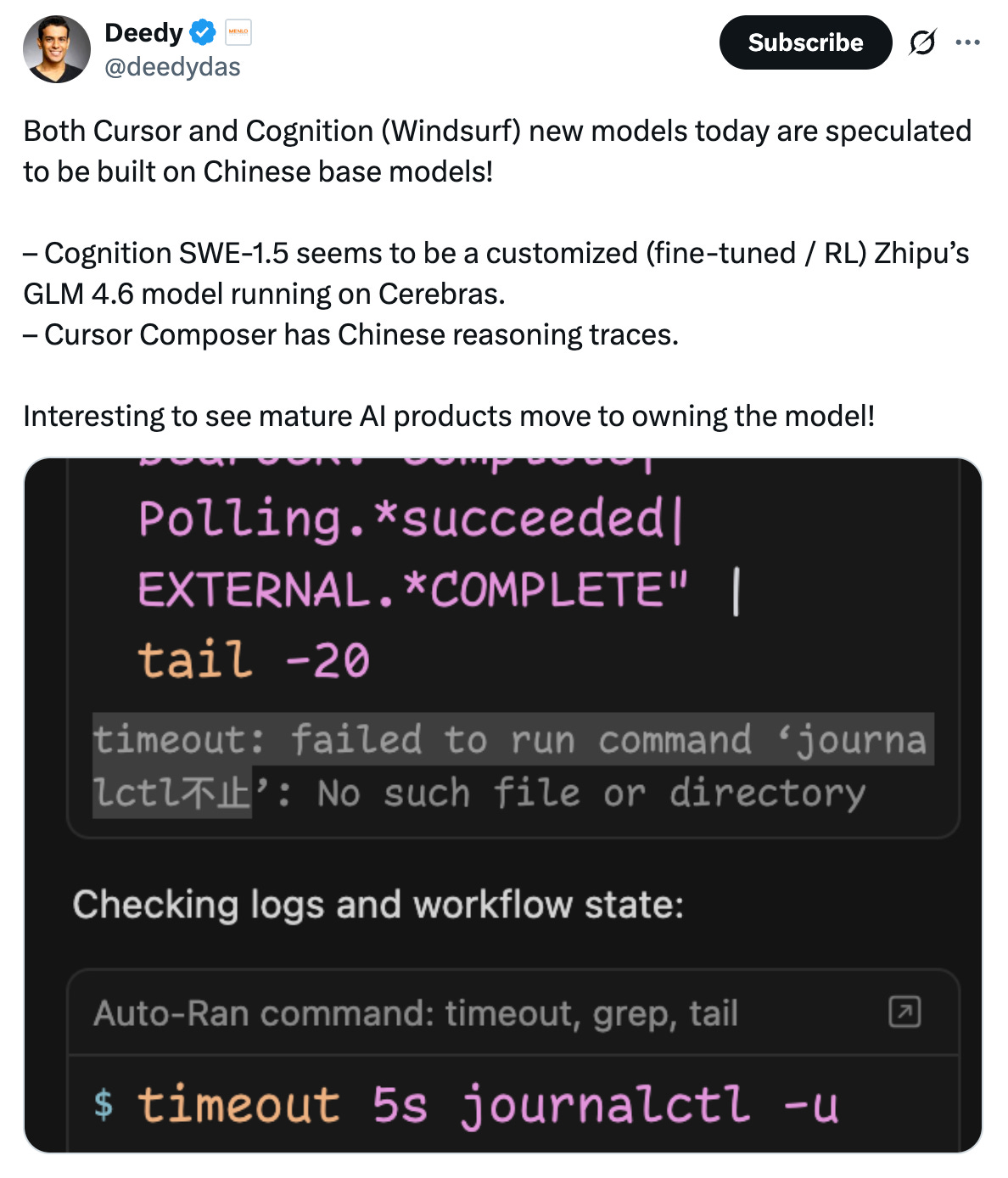
Later one Menlo Ventures partner put it:
Both Cursor and Cognition (Windsurf) new models today are speculated to be built on Chinese base models!
– Cognition SWE-1.5 seems to be a customized (fine-tuned / RL) Zhipu’s GLM 4.6 model running on Cerebras.
– Cursor Composer has Chinese reasoning traces.
Mid-tier AI application startups don’t have the capital or compute to train foundation models from scratch. Even organizations with far deeper pockets have tried and failed.
So they’re building on top of open-source LLMs and pour resources into reinforcement learning and post-training where their strong, uniquely collected user data gives them an advantage.
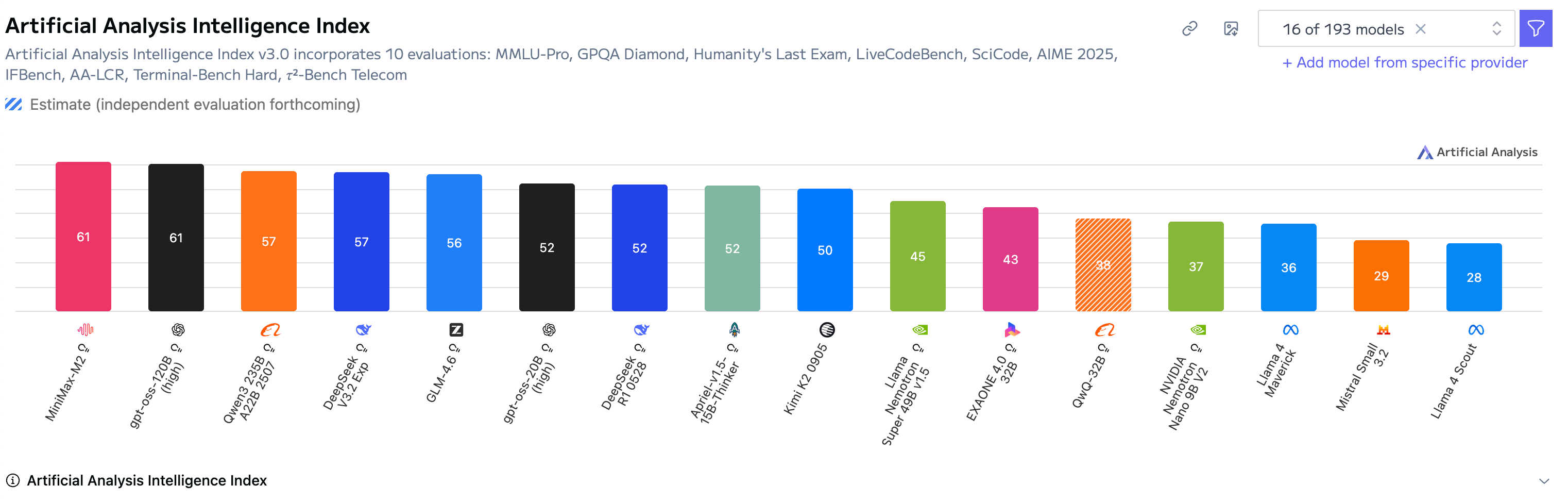
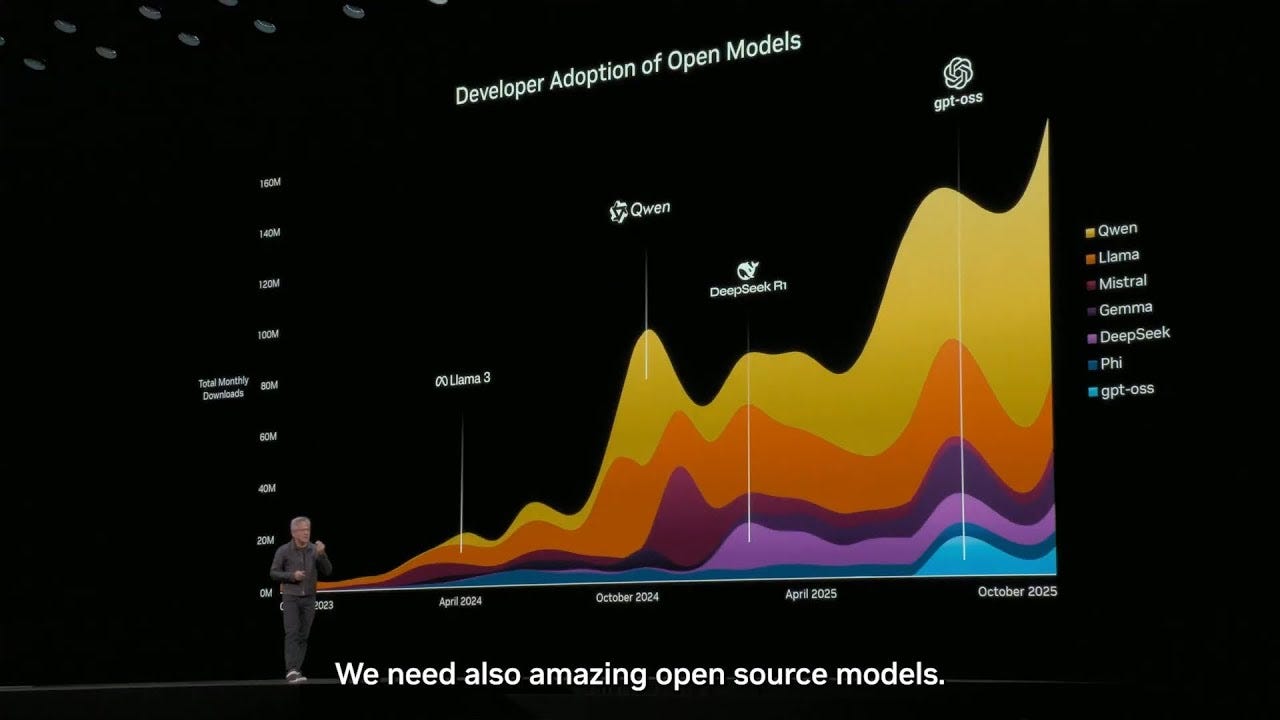
One year ago, these U.S. companies would probably choose Meta’s Llama or Mistral models as their foundation, but today Chinese AI labs are dominating the open-source leaderboard. As of November, 2025, four of the top five open-source models come from MiniMax, Alibaba, DeepSeek, and Z.ai, according to Artificial Analysis Intelligence Index.
At GTC DC in October, Nvidia CEO Jensen Huang said that Alibaba’s Qwen leads all open models in monthly downloads, and its market share keeps climbing.
Nvidia CEO Jensen Huang speaks at GTC DC on October 29, 2025. Source: Nvidia
U.S. Companies Publicly Choosing Chinese LLMs
Performance and cost are starting to matter more than geopolitics in LLM choices in Silicon Valley.
Chamath Palihapitiya, the Social Capital founder and All-In Podcast co-host, revealed that his team migrated significant workloads to Kimi K2 from Moonshot AI running on Groq because “it was way more performant and frankly just a ton cheaper than both OpenAI and Anthropic.”
Of course Palihapitiya was actually advocating for Groq, a U.S. AI startup building chips for AI inference workloads, as Social Capital was an early investor of Groq. But his comment inadvertently exposed a growing reality: cost and performance is overtaking geopolitics.
The cost gap is staggering. Kimi K2’s input costs ($0.60 per million tokens on OpenRouter) run less than one-fifth of Claude Sonnet 4’s price. Output costs ($2.50 per million tokens) are as low as one-seventh.
Meanwhile, Airbnb CEO Brian Chesky, who is a longtime Sam Altman ally, told Bloomberg last month that his company “relies a lot on Alibaba’s Qwen model” for their AI customer service agent, which combines 13 different models.
“We use OpenAI’s latest models,” Chesky added, “but we typically don’t use them that much in production because there are faster and cheaper models.”
Quick Takeaway
Let’s put the geopolitics and ideological aside: Would it actually make sense for builders to ignore high-performing, cost-effective models simply because of where they came from?
One common fear about adopting Chinese open-source models has been content moderation. Meta CEO Mark Zuckerberg once argued that Chinese LLMs are “inherently censored and undemocratic.”
But here’s the nuance: Kevin Xu from Interconnected tested DeepSeek and Qwen models both locally and on cloud platforms. He discovered the models are notably more candid when run locally compared to their cloud-hosted versions, which do show signs of content filtering.
In addition, for the use cases we’re discussing, including Cursor’s coding agents and Palihapitiya’s AI workloads, content moderation is largely irrelevant. You’re asking these models to debug code or route an inquiry, not answering sensitive questions.
Chinese AI labs also recognize this trend. Alibaba, MiniMax, Z.AI, and Moonshot AI are all doubling down on agentic and coding capabilities.
As Chinese AI labs crush benchmarks, Silicon Valley’s most sophisticated developers are accordingly integrating those models into products millions of people use daily.
At the end, I wanted to share what Wang Jian, Alibaba’s former CTO who founded its cloud business, said in one of his recent keynote addresses:
Opening up model weights today is essentially opening access to data resources and compute resources. Once the model is open, you no longer need to spend massive compute power to redo what others have already done for you.
What I want to emphasize is that after things become open, large-scale computation doesn’t suddenly become unimportant. Instead, as an individual you no longer need to invest so many resources yourself, because someone has already paid that cost for you. On the flip side, to build a better model, it may require others to invest in more resources to accomplish the task.
Today, simply open-sourcing code no longer solves the same problems it did in the software era. What truly drives this industry forward is opening resources, especially data and compute. That’s the essential characteristic of “open source” in the AI era. I actually prefer calling it “Open Resource.” In Chinese, both “Open Source” and “Open Resource” translate to the same word, “开源” (kāiyuán). Of course, open source today goes far beyond just model code.
Wang Jian speaks at the 2025 Inclusion·Conference on the Bund on September 11, 2025. Source: Zhihu
Wang Jian's distinction between open source and open resource is brilliant and often missedby Western observers. Alibaba's Qwen dominating downloads while Airbnb uses it in production shows that performance and cost economics will always win over ideology. The fact that Cursor and Cognition are quietly building on DeepSeek and GLM validates that Chinese LLMs have crossed the threshold from experimental to production grade infrastructure.






Wang Jian's distinction between open source and open resource is brilliant and often missedby Western observers. Alibaba's Qwen dominating downloads while Airbnb uses it in production shows that performance and cost economics will always win over ideology. The fact that Cursor and Cognition are quietly building on DeepSeek and GLM validates that Chinese LLMs have crossed the threshold from experimental to production grade infrastructure.