
💻Kimi K2: Smarter Than DeepSeek, Cheaper Than Claude
Kimi K2 may be the first agentic model that China’s agent developers have been waiting for.


Hi, this is Tony! Welcome to this issue of Recode China AI, your go-to newsletter for the latest AI news and research in China.
Beijing-based AI startup Moonshot AI (or “Moonshot”) has just released Kimi K2, its most ambitious open-source large language model (LLM) to date. With a whopping 1 trillion parameters, Kimi K2 delivers state-of-the-art performance among open LLMs across coding, math, tool use, and agentic tasks, while closing gaps against top closed models from OpenAI and Anthropic.
Early reactions on social media are overwhelmingly positive. Perplexity CEO Aravind Srinivas noted:
“Kimi models are looking good on internal evals. So we’ll likely begin post-training on it pretty soon.”
The excitement is reminiscent of earlier this year when DeepSeek-V3 and R1 made headlines. Could Moonshot be engineering its own “DeepSeek moment”—another scenario where a Chinese AI lab dominates the open-source leaderboard?
An Open, Cheaper Claude Sonnet 4?
Kimi K2 is built on a Mixture-of-Experts (MoE) architecture with 1 trillion total parameters, 32 billion of which are activated per forward pass. It comes in two versions:
Kimi-K2-Base: a pre-trained base model;
Kimi-K2-Instruct: an instruction-tuned version optimized for general-purpose chat and agentic reasoning.
The model is released under a Modified MIT License, one of the most permissive open-source licenses. However, if a product or service built on Kimi K2 exceeds 100 million MAUs or $20 million in monthly revenue, it must credit “Kimi K2” in its UI.
Kimi K2 shows particular strength in both front-end and agentic tasks. On the front-end, it can generate complex UI simulations such as climate simulation and 3D particle interactions.
The model can also understand and execute complex, multi-step instructions, by decomposing a task into a structured series of executable tool calls, from search to calendar and restaurant bookings. This makes Kimi K2 well-suited for automating complex workflows.
Users can integrate the model’s API with coding apps such as Cursor and Claude Code, and agent frameworks such as Owl, Cline, and RooCode.

As one Moonshot insider revealed, initially, the team attempted direct MCP (Model Context Protocol) integration with tools like Blender and Notion. However, infrastructure challenges and API authentication barriers made real-world training difficult. This led to a shift based on a hypothesis:
The model had likely already learned how to use tools during pretraining—we just needed to activate that skill.
To achieve this, Moonshot researchers created a large-scale pipeline to simulate diverse tool-use scenarios across hundreds of domains. The training approach leverages multi-agent interactions and rubric-based evaluation, producing high-quality datasets for tool-centric learning and agent behavior modeling.
On the cost side, Kimi K2’s input API price, $0.60 per million tokens (on OpenRouter) , is less than one-fifth of Claude 4 Sonnet’s, and output costs, $2.50 (on OpenRouter) per million tokens, are as low as one-seventh.
Built on DeepSeek-V3’s Architecture

For readers curious about what fundamental innovations Kimi K2 brings to the table, the answer may be underwhelming: it uses nearly the same architecture as DeepSeek-V3.
The differences are subtle. Kimi K2 is more sparse than DeepSeek-V3, activating only 8 experts out of 384 per forward pass. Additionally, it omits the double-head mechanism in DeepSeek’s design.
That’s not a criticism. By building on proven designs with proper attribution, Moonshot has delivered a model that is more efficient, and arguably more capable.
Another Moonshot’s insider shared the behind-the-scene thinking: Rather than chasing novelty for novelty’s sake, the team decided to retain a proven base and focus on what they could control: parameter scaling, optimizer tuning, and inference cost.
Before starting K2 training, we conducted a large number of scaling experiments related to model architecture. The result was that none of the architectures proposed at the time, which differed from DSv3, were able to truly outperform it (at best, they were on par). So the question became: should we, for the sake of being different from DeepSeek, deliberately choose an architecture that has no clear advantage but is simply "different"? The final answer was no.
….
So we established the first design constraint: fully inherit DSv3's architecture, and adjust structural parameters to suit our model.
The second constraint was cost, including both training and inference costs. Again, the reason is straightforward: as a small company, our resources for training and inference are very limited.
MuonClip Optimizer
Training a 1-trillion-parameter MoE model posed significant optimization challenges, which Moonshot tackled with a custom solution called MuonClip.
MuonClip builds upon Moonshot’s earlier Muon optimizer, which has been proved effective on a 16-billion-parameter model. It further introduces novel stabilization techniques that allowed Kimi K2 to be trained on a colossal 15.5 trillion token dataset without any training instability or loss spikes.
This is remarkable as ultra-large MoE models are known to suffer from divergence or “exploding loss” if not carefully managed. Here is what Moonshot’s technical report explained:
To address this, we introduce the MuonClip optimizer that improves Muon with our proposed qk-clip technique. Specifically, qk-clip stabilizes training by directly rescaling the weight matrices of the query and key projections after Muon updates, thus controlling the scale of attention logits at the source…
Our experiments show that MuonClip effectively prevents logit explosions while maintaining downstream task performance. In practice, Kimi K2 was pre-trained on 15.5T tokens using MuonClip with zero training spike, demonstrating MuonClip as a robust solution for stable, large-scale LLM training.
By solving the instability at the source, they achieved a smooth training curve, which one researcher called “every ML engineer’s dream loss curve” with no sudden spikes.
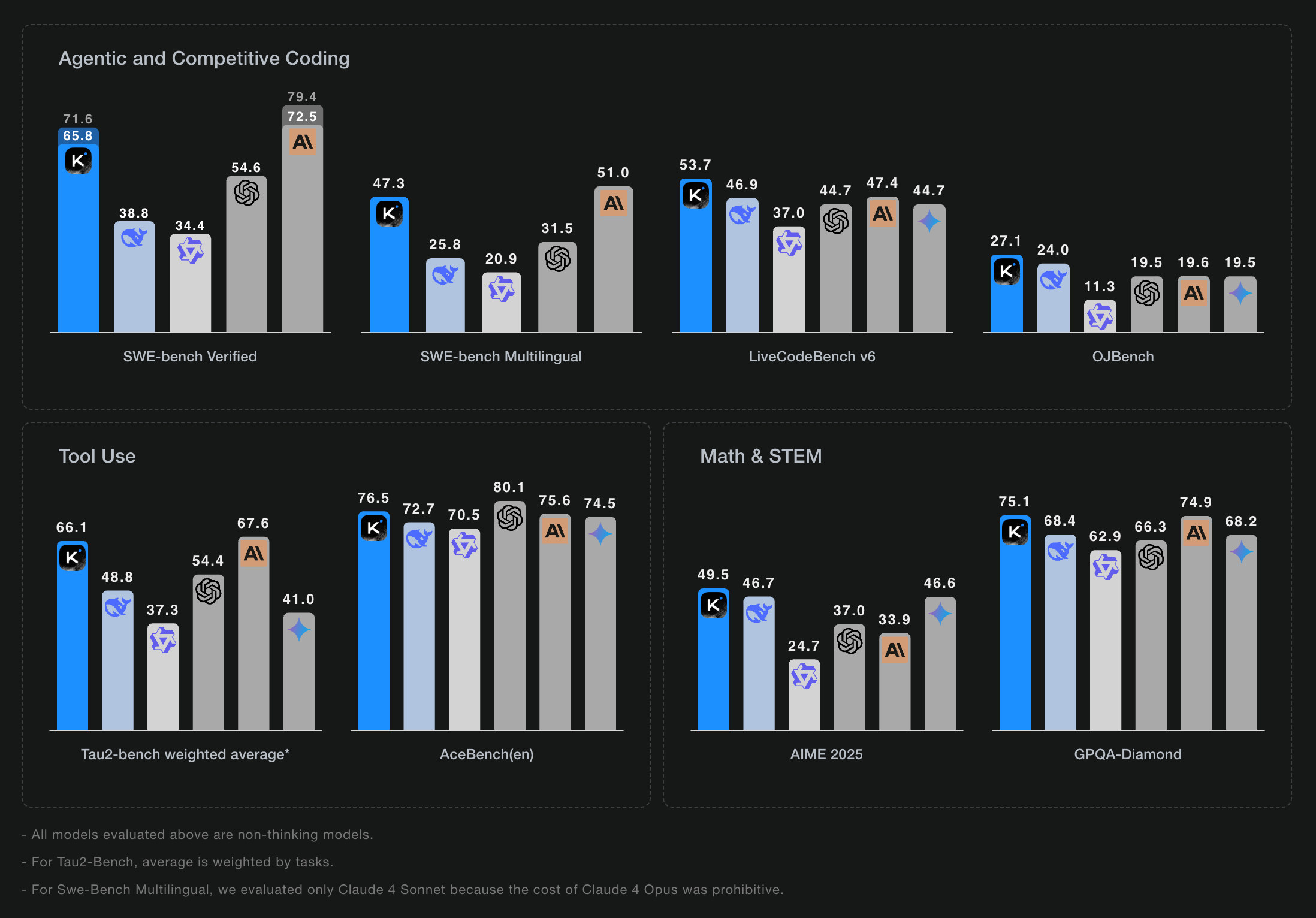
Benchmark Performance
Coding:
LiveCodeBench v6: 53.7% pass@1 (GPT-4.1: 44.7%; Claude Opus 4: ~48.5%)
OJBench: 27.1% (Claude: 15%)
Agentic Tasks:
SWE-Bench (single-attempt): 65.8% (DeepSeek-V3: 38.8%; Claude Sonnet 4: 72.7%)
SWE-Bench Multilingual: 47.3% (DeepSeek-V3: 25.8%; Claude Sonnet 4: 51.0%)
Math & Reasoning:
MATH-500: 97.4% (DeepSeek-V3: 94.0%)
AIME 2024: 69.6% (DeepSeek-V3: 59.4%)
CNMO 2024: 74.3% (DeepSeek-V3: 74.7%)
General Knowledge:
MMLU: 89.5% (Claude Opus 4: 92.9%)
Humanity’s Last Exam: ~4.7/10 (Claude Opus 4: 7.1)
Moonshot’s Roller Coaster Ride

Moonshot began as a relative unknown in China’s LLM race following the release of ChatGPT. Founded in March 2023 by Tsinghua alumni Yang Zhilin, Zhou Xinyu, and Wu Yuxin, the company launched with a modest $60 million seed round and roughly 40 employees. Its debut product, the Kimi chatbot, was released in October 2023 and featured a 200K-character context window—but the initial launch failed to gain widespread attention.
That changed in 2024. In February, Moonshot shocked the industry by securing a $1 billion Series B led by Alibaba, pushing its valuation to $2.5 billion. By August, Tencent and Gaorong Capital joined a $300 million follow-on round, raising the company’s valuation further to $3.3 billion.
Kimi’s breakout came in March 2024, when the chatbot was upgraded to support 2 million Chinese characters per prompt—an order-of-magnitude leap that drove massive interest and even caused a temporary system outage on March 21 due to surging demand.
Beyond its chatbot, Moonshot CEO Yang had been widely recognized as China’s most promising young AI leader. A Tsinghua- and CMU-trained researcher and author of two influential Transformers papers, Yang is also a rock music amateur—he named the company after Pink Floyd’s The Dark Side of the Moon. With a flair for ambition, he has drawn comparisons to Sam Altman for his bold vision of building AGI.
AGI is the only thing that matters over the next decade.
The company also backed its chatbot with an aggressive advertising push, reportedly spending over 400 million RMB (~$55 million) in October and November 2024. As a result, Kimi became one of China’s top two most popular chatbot apps.
But the momentum didn’t last. In January 2025, DeepSeek-R1 launched with no advertising budget, yet quickly overtook ChatGPT on the App Store and became a dominant player. Moonshot wasn’t idle—around the same time, it introduced Kimi 1.5, which also demonstrated that as reinforcement learning training progressed, response length and accuracy improved. But DeepSeek-R1’s momentum overshadowed Moonshot. The latter’s advertising strategy was criticized as a distraction.
The company also came under fire for its controversial spin‑off from Recurrent Intelligence, Yang’s last company, sparking arbitration by GSR Ventures and four other investors over alleged governance and conflict‑of‑interest breaches. It was also flagged by China’s cybersecurity regulator for over‑collecting user data via its Kimi chatbot.
By June 2025, Kimi had slipped to seventh place in China’s AI product rankings. Moonshot quietly scaled back its PR and advertising efforts and redirected its resources toward technological innovation.
(Once again, ChinaTalk was ahead of the curve with an translation of a long piece on Moonshot—well worth a read.)

My Last Takeaway
What makes Kimi particularly interesting—and what Moonshot has proven adept at—is differentiation. As Nathan Lambert said in his newsletter:
AI adoption and market share downstream of modeling success comes from differentiation in AI.

Kimi went viral in 2024 as the most capable long-context chatbot at the time. Now, Kimi K2 is gaining attention for its exceptional performance in coding and agentic tasks—precisely the gap that had long existed in China’s model landscape. As MIT Technology Review previously reported:
An engineer overseeing ByteDance’s work on developing an agent, who spoke on condition of anonymity, said the absence of Claude Sonnet models “limits everything we do in China.” DeepSeek’s open models, he added, still hallucinate too often and lack training on real-world workflows. Developers we spoke with rank Alibaba’s Qwen series as the best domestic alternative, yet most say switching to Qwen knocks performance down a notch.
Could Moonshot and Kimi K2 become China’s answer to Claude Sonnet and power the next generation of AI agents?