
💡Will DoT Replace CoT, ByteDance Enters AI Video War, and China's Ready for 100K GPU Clusters
Weekly China AI News from September 23, 2024 to October 6, 2024

Hi, this is Tony! Welcome to this week’s issue of Recode China AI, a newsletter for China’s trending AI news and papers.
Three things to know
Researchers from Tsinghua University led by Andrew Chi-Chih Yao introduce Diagram of Thought (DoT) that could replace Chain of Thought (CoT).
ByteDance releases two new video generation AI models.
Chinese tech giants like Alibaba, Tencent, and Baidu, have upgraded their computing platform to support 100,000 GPUs.
Chinese Researchers Propose Diagram of Thought to Overshadow Reasoning Technique Behind OpenAI’s o1

What’s New: Last week researchers from Tsinghua University, led by the legendary Chinese computer scientist Andrew Chi-Chih Yao, introduced a novel framework, Diagram of Thought (DoT), designed to enhance the reasoning capabilities of LLMs.
Limitations of Chain-of-Thought: The paper’s authors argued while LLMs have excelled in various tasks, their capacity for complex reasoning remains limited. For example, Chain-of-Thought (CoT), the reasoning technique behind OpenAI’s o1 model, represent reasoning as linear sequences. This means they process information in a straight line, similar to following a recipe. While this can be effective for some tasks, it doesn’t reflect the way of how humans think, which is often non-linear and iterative.
Imagine solving a puzzle: you don’t just place pieces in order; you try things out, might need to backtrack, and adjust your approach based on new information. This is iterative thinking in action. Also our thoughts don’t always follow a straight line. We might jump back and forth between ideas, make connections between seemingly unrelated concepts, or explore different possibilities at the same time.
While extensions like Tree-of-Thought (ToT) and Graph-of-Thought (GoT) introduce branching structures, they can be computationally expensive and challenging to implement within a single LLM, the authors argue.
What is Diagram of Thought (DoT): DoT addresses these limitations by modeling reasoning as the construction of a directed acyclic graph (DAG) within a single LLM. This DAG comprises nodes representing:
Propositions: Initial and refined ideas generated throughout the reasoning process.
Critiques: Evaluations of propositions, identifying errors or inconsistencies.
Refinements: Improved propositions based on critiques.
Verifications: Confirmation of valid propositions.
Think of a DAG like a flowchart: With DAG, the model can explore multiple ideas or solutions. The critique nodes allow the model to evaluate its own reasoning and make corrections, just like we reflect on our own thoughts. Because DAG is a structure where information flows in one direction, it prevents the model from getting trapped in circular reasoning.
DoT leverages auto-regressive next-token prediction with role-specific tokens (e.g., <proposer>, <critic>, <summarizer>) to manage the reasoning process within a single LLM. This eliminates the need for multi-LLM collaboration or external control mechanisms.
Another crucial aspect of the DoT framework is its strong foundation in mathematical logic. The paper formalizes DoT using Topos Theory, providing a mathematical framework that ensures logical consistency and soundness in the reasoning process.
ByteDance Joins AI Video War with Two New Models
What's New: On September 24, 2024, ByteDance released two new video generation AI models named Doubao-PixelDance and Doubao-Seaweed. The models aim to compete with OpenAI’s Sora by narrowing the performance gap between Chinese and Western video generator.
The PixelDance model focuses on producing complex and sequential motions, capable of generating 10-second videos, while the Seaweed model extends that capacity up to 30 seconds. Both models are currently undergoing small-scale testing, but will soon be made available to enterprise markets and a broader user base.
How It Works: According to ByteDance, these two new video generators are both Diffusion Transformer (DiT) model, similar to Sora and Kuaishou’s Kling. The models leverage the Douyin (TikTok’s China version) and Jianying (CapCut’s China version) platforms’ video understanding capabilities. They also support multiple visual styles - ranging from 3D animation to traditional Chinese painting and watercolor - and can handle different screen ratios.
One major selling point is the stability and consistency of video generation. The models can generate videos that transition smoothly from one shot to another - whether it involves zooming, panning, rotating, or tracking a target - something that remains a significant challenge for other video generators. The generated characters can perform a wide range of complex movements. Multiple characters can even interact naturally within the scene.
While ByteDance didn’t disclose technical details during the release, its researchers released a paper of PixelDance a year ago. PixelDance is a diffusion model-based approach leveraging image instructions for the first and last frames of a video, alongside text instructions. This approach enables the model to focus on learning motion dynamics and generating complex movements.
Why It Matters: While it’s still difficult to tell whether ByteDance’s video generators are a valid Sora challenger given the limited amount of video demos, they are definitely one of the strongest contenders in China and opens up new creative possibilities for content creators in China.
China Tech Giants Ready to Support 100,000 GPU Clusters

What’s New: Chinese tech giants are entering the race for 100,000 GPU clusters - a critical milestone for AI model development as these clusters provide the computational power necessary to train increasingly complex and large-scale AI models like GPT-5.
On September 25, Baidu’s Executive Vice President Shen Dou announced at the Baidu AI Cloud Summit that “soon more 100,000-GPU clusters will emerge,” as demand for larger-scale model training continues to rise. Baidu unveiled its upgraded heterogeneous computing platform, Baige 4.0, designed to manage this ambitious scale. Alibaba Cloud and Tencent are similarly scaling up to support 100,000-GPU clusters.
The move comes on the heels of recent developments by other global players. Elon Musk’s xAI deployed a 100,000 Nvidia H100 GPU cluster, with plans to double it within months. Meanwhile, Meta CEO Mark Zuckerberg revealed that Meta’s compute power will reach the equivalent of 600,000 H100 GPUs.
Technical Challenges: Building a 100,000-GPU cluster involves more than simply scaling up existing setups. These clusters must solve issues related to high-performance computation, power consumption, and physical space. Shen highlighted that managing such a cluster requires about 100,000 square meters - equivalent to 14 soccer fields - and consumes nearly 3 million kWh of electricity per day, comparable to the daily power usage of one Beijing district with over 700,000 people.
Beyond the physical infrastructure, efficient GPU use is crucial. Key challenges include inter-GPU networking, hardware-software optimization, and managing system stability. For instance, the probability of hardware failures increases with the number of GPUs involved. Shen noted that at Meta, their 16,000-GPU cluster for training Llama often experiences failures every 2-3 hours. Such challenges are magnified when operating clusters as large as 100,000 GPUs.
Why It Matters: 100,000-GPU clusters are becoming the entry ticket to the future of generative AI. As models grow in size and complexity, traditional 10,000-GPU clusters are no longer sufficient. Companies without the compute power of at least 10,000 GPUs are increasingly seen as lagging behind in the AI race.
The pursuit of massive clusters comes with immense costs, both in terms of money and energy. For AI to truly advance, addressing cost efficiency and effective GPU utilization is key. Oracle Founder Larry Ellison once said that training costs for AI models, which today reach $1 billion, could grow to $100 billion in the coming years.
Weekly News Roundup
Tencent Robotics X Lab has introduced The Five, a versatile home robot designed with a hybrid locomotion system combining wheels and legs for efficient and adaptable movement. (TechNode)
China Telecom, a state-owned telecommunications company, has revealed the creation of two LLMs, the TeleChat2-115B and an unnamed model with 1 trillion parameters, which have been trained exclusively using domestically produced Chinese chips. (South China Morning Post)
Huawei has initiated the distribution of its latest artificial intelligence chip, the Ascend 910C, to major Chinese server companies for hardware testing. (South China Morning Post)
Yang Qiumei, the widow of SenseTime cofounder Tang Xiao’ou, has inherited a $1.6 billion stake in the AI giant, making her a billionaire and a new addition to Hong Kong's list of wealthiest individuals. (Forbes)
Trending Research

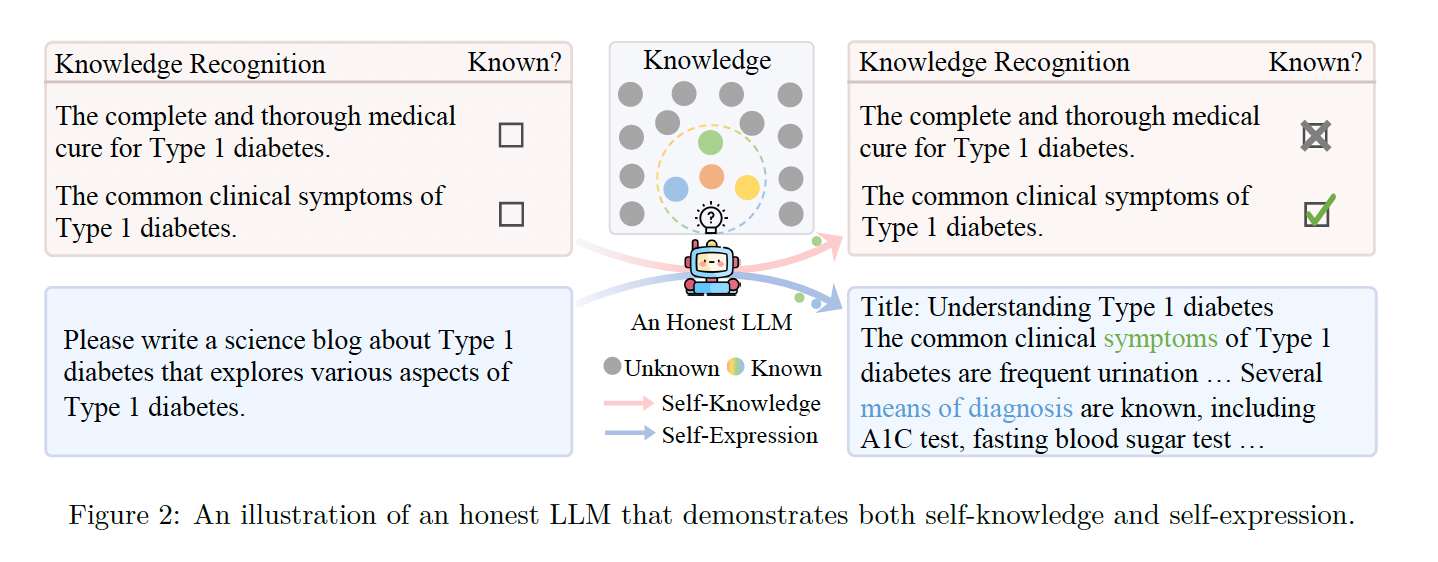
A Survey on the Honesty of Large Language Models
This research survey examines the honesty of LLMs, exploring the concept of honesty in LLMs, how to evaluate their honesty, and methods to improve their honesty. The authors argue that honesty is a fundamental principle for aligning LLMs with human values and is particularly important in high-stakes domains like medicine and finance. An honest LLM should not only provide truthful and reliable information to users, but also acknowledge their limitations, recognize their own knowledge boundaries and refrain from fabricating information. They also address challenges in defining honesty and evaluating LLMs, and propose potential directions for future research in this field.


MIO: A Foundation Model on Multimodal Tokens
This research paper introduces MIO, a novel foundation model that leverages multimodal tokens to understand and generate speech, text, images, and videos in an end-to-end, autoregressive manner. MIO addresses the limitations of existing models by achieving any-to-any understanding and generation. This capability allows for tasks like interleaved video-text generation and visual guideline generation. The paper details the model’s architecture, including its training process, which involves stages focusing on alignment, interleaving, and speech enhancement. It also presents extensive experimental results showcasing MIO’s competitive performance on various benchmarks.

Emu3: Next-Token Prediction is All You Need
This research paper introduces Emu3, a multimodal AI system trained solely on next-token prediction. Emu3 utilizes a transformer model to process images, text, and videos, achieving state-of-the-art performance in both generation and perception tasks. The authors showcase Emu3’s capabilities in generating high-fidelity images, videos, and even predicting future video frames. They also demonstrate its strong understanding of vision-language, outperforming models that rely on pre-trained encoders. This research highlights the potential of next-token prediction as a powerful paradigm for creating general multimodal intelligence.
Thanks, this is a really good source of news.