
🌪️Sora vs. Chinese Video Generators, ByteDance-Sued Intern Wins NeurIPS Best Paper, and New Chinese AI Gaming Model Unveiled
Weekly China AI News from December 9, 2024 to December 15, 2024

Hi, this is Tony! Welcome to this week’s issue of Recode China AI, a newsletter for China’s trending AI news and papers.
Three things to know
OpenAI’s Sora now faces stiff competition from Chinese AI video generators.
The paper co-authored by a ByteDance-sued intern wins the NeurIPS Best Paper.
Chinese game developer Giant Network unveils an AI model for interactive open-world game environment.
OpenAI’s Sora vs Chinese Video Generators

What’s New: After a 10-month delay, OpenAI last week launched its widely-anticipated AI video generation model, Sora. In the intervening months, competing Chinese AI video generators like Kuaishou’s Kling, MiniMax’s Hailuo, and Shengshu’s Vidu have made significant strides. They introduce unique features such as multi-frame editing and stylized animations, while attract users with competitive pricing and free trials (The Information did a good story.) Sora now faces stiff competition, and users are eager to see how it stacks up.
How It Works: To assess Sora’s capabilities, one Chinese media conducted a series of side-by-side comparisons against other models in key scenarios:
Round 1: Sora vs. Kling
A golden retriever in an art gallery (T2V): Sora and Kling were both impressive in terms of lighting, texture, and motion realism. Me personally speaking, Sora’s generation, which was cherrypicked, feels more real.


A human-like black dog wearing a yellow raincoat (I2V): Sora’s cinematic montage showcased advanced editing finesse, while Kling produced smoother motion.




Round 2: Sora vs. Kling & Hailuo
Pyramids and apocalypse (I2V): Sora and Kling leaned into dystopian themes, whereas Hailuo embraced a fantasy battle aesthetic.



Viking actor’s close-up: The prompt is the Viking actor’s emotional expression, with the camera zooming in on the actor’s furrowed face. While Sora experimented with camera angles, Kling and Hailuo captured nuanced facial expressions.



Lunar activities: This prompt lets the models imagine the activities of astronauts on the moon. Sora excelled in dynamic scene transitions, Kling prioritized detail, and Hunyuan delivered the most coherent narrative.



Why It Matters: While Sora excels in cinematic transitions and creativity, it faces challenges in logical coherence and natural fluidity. Its image-to-video generation also lags behind competitors like Runway and Kling, some users claimed. Pricing could also be a sticking point: at $20/month for Plus users and $200/month for Pro users, the latter offering higher resolution and watermark-free options, OpenAI targets professional creators but risks alienating casual users.
ByteDance-Sued Intern Wins NeurIPS Best Paper

What’s New: The paper co-authored by a former ByteDance intern who was sued by TikTok’s parent company for sabotaging its AI training just won the prestigious Best Paper Award at the 2024 Neural Information Processing Systems (NeurIPS) conference last week.
Keyu Tian is a master of science student at Peking University, studying under PhD advisor Liwei Wang, who is also a co-author of the paper. In August 2024, ByteDance dismissed Tian for allegedly sabotaging AI research projects and interfering with model training tasks. The company filed a lawsuit against him in Beijing, seeking 8 million yuan (approximately $1.1 million) in damages and a public apology. Check out our previous story for more details.
🧐Is TSMC Producing Huawei’s AI Chip? ByteDance Fires Intern for Sabotaging AI, Plus IPO Frenzy Among Chinese Self-Driving Startups

Hi, this is Tony! Welcome to this week’s issue of Recode China AI, a newsletter for China’s trending AI news and papers.
Despite the controversy, the research, co-authored with researchers from ByteDance and Peking University, marks the first time GPT-style autoregressive models surpass diffusion transformers in visual generation, a feat widely regarded as transformative in the AI community.
How It Works: In the paper Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction, the VAR framework challenges the conventional image generation paradigm by shifting from next-token predictions to multi-scale “next-scale prediction”. Here’s how it works:
Multi-Scale Approach: Instead of flattening 2D image data into 1D sequences, VAR processes images hierarchically. The model begins by generating a coarse-resolution token map and incrementally adds finer details.
Efficiency and Performance: VAR achieves a Fréchet Inception Distance (FID) of 1.73 on the ImageNet benchmark—a significant improvement over previous autoregressive models. It’s also 20 times faster in inference compared to diffusion models like Stable Diffusion.
Scaling Laws: By mimicking the scaling behaviors of large language models (LLMs), VAR achieves better performance as the model’s size increases, adhering to predictable power-law trends. This scalability supports high-quality image generation even with fewer computational resources.
Zero-Shot Generalization: VAR extends its utility to tasks like image in-painting, out-painting, and editing without additional fine-tuning, showcasing adaptability across diverse applications.
Why It Matters: VAR could reflect a turning point in the domain of visual generation, which has long been dominated by diffusion models. By bridging concepts from LLMs into computer vision, the research demonstrates that GPT-style architectures are viable contenders for state-of-the-art visual tasks.
Meanwhile, Tian’s previous unethical behaviors at ByteDance also sparked debate in the AI community, with some calling for the revocation of this paper due to the allegations against Tian.
China’s Giant Network Unveils AI Generator for Open-World Games
What’s New: Last week, Giant Network, a Chinese online game developer, introduced YingGame, an AI video generator model designed for interactive open-world game environment.
Jointly developed with Tsinghua University, this model enables developers to create interactive game worlds using only text and images, bypassing traditional game engines. It can generate video game scenes with high-fidelity physical simulations and controllable characters that interacts with their virtual environment.
Meanwhile, Giant Network also released YingSound, a multi-modal sound generation model that can sync sound effects with video gameplay. Together, these two models aim to democratize game creation.
How It Works: To customize game characters that can perform comprehensive actions and motions, YingGame integrates multiple techniques such as cross-modal feature fusion, fine-grained character representation, motion enhancement, and multi-stage training. Its key components include:
Multi-Modal Interactive Network (MMIN): Facilitates rich action control by interpreting user inputs, such as text, images, or keyboard commands.
Interactive Character Network (ICN): Enables character customization with exceptional visual fidelity and realism.
Interactive Motion Network (IMN): Ensures fluid, continuous character actions that adhere to physical laws.
YingGame’s training data pipeline includes generating high-quality video clips, filtering them based on motion and aesthetics, and using vision LLM-based captioning for precise text-video alignment.
For sound, YingSound employs a DiT-based flow-matching framework and a multi-modal chain-of-thought (CoT) approach to achieve seamless audio-visual integration. It excels in generating sound effects tailored to video contexts, whether in-game, animated, or real-world scenes.
Why It Matters: While the full impact remains uncertain, Giant Network’s innovation has the potential to streamline video game development, a process that has become increasingly resource-intensive, time-consuming, and risk-averse. China’s video gaming industry revenue in 2024 grew 7.53 per cent to $44.8 billion.
AI gaming has gained significant momentum this year. Google DeepMind’s Genie 2, a state-of-the-art foundation world model, can generate fully playable 3D environments from a single prompt image. Complementing this, the company’s SIMA (Scalable Instructable Multiworld Agent) is an advanced AI agent understanding and interacting with 3D virtual environments by following natural-language instructions.
(Bi-)Weekly News Roundup
China’s Ministry of Industry and Information Technology has established an AI standardisation committee with executives from major tech companies like Baidu, Alibaba, Tencent, and Huawei, aiming to develop AI standards by 2026. (South China Morning Post)
Hong Tao, a co-founder and key figure in monetisation at Chinese AI start-up Baichuan, has departed amidst a competitive domestic AI industry landscape. (South China Morning Post)
Although ByteDance's AI chatbot Doubao has become the second most popular globally, the company reportedly views AI video generators as a higher priority for growth. This strategic focus is reflected in their internal memo and aligns with the insights from local media reports. (South China Morning Post)
Apple is collaborating with Baidu to enhance iPhones with AI features tailored for Chinese users, aiming to boost sales in a competitive market. (The Information)
Trending Research
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Researchers from Tencent introduce HunyuanVideo, an open-source video generation framework that rivals or exceeds the performance of leading closed-source models, with a scalable architecture supporting models with over 13 billion parameters.
DeepSeek-VL2 is an advanced series of Mixture-of-Experts (MoE) Vision-Language Models designed for enhanced multimodal understanding, offering competitive performance with fewer parameters compared to existing models.
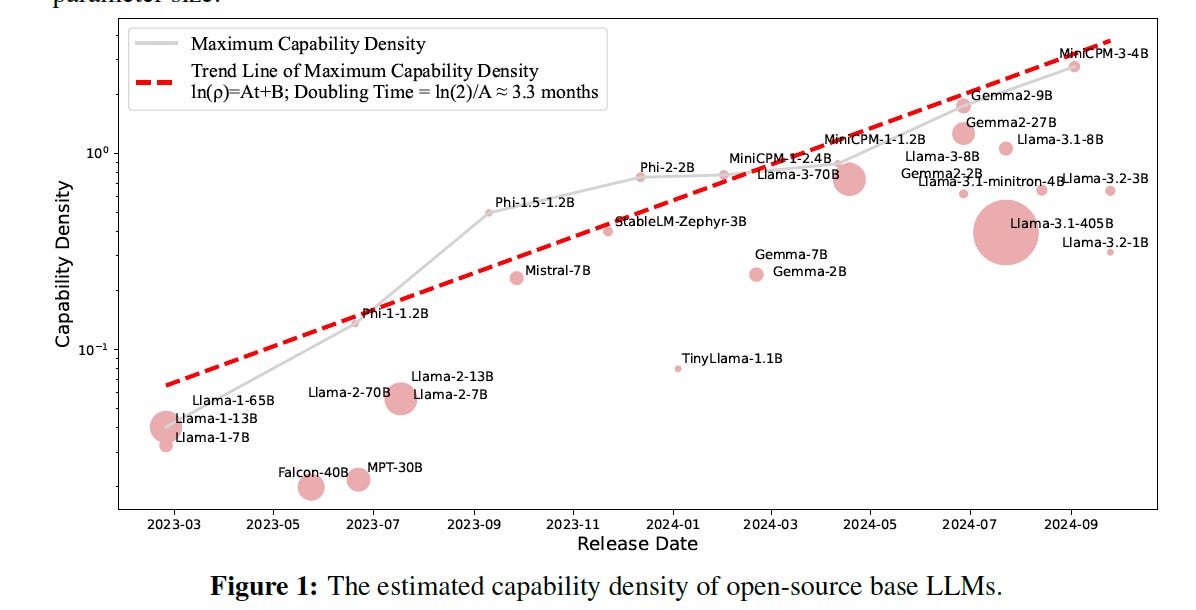
Researchers from Tsinghua University and ModelBest introduce the Densing Law of LLMs, which posits that the capacity density of LLMs grows exponentially over time, doubling approximately every three months, and proposes a new metric called capacity density to assess the quality of LLMs in terms of both effectiveness and efficiency.
Interesting text to video comparisons. China's prowess in text to video is certain to improve in 2025. Runway and Luma will have stiff competition.