
♾How Huawei Trains DeepSeek-R1-Class LLMs Using Its Own Ascend Chips
Pangu Ultra MoE is an AI model featuring 718 billion parameters trained with over 6,000 Ascend NPUs.


Hi, this is Tony! Welcome to this issue of Recode China AI, your go-to newsletter for the latest AI news and research in China.
Since the U.S. imposed restrictions specifically targeting Huawei’s access to advanced chips and chip manufacturing technology—critical for training cutting-edge AI models—the Chinese telecom and smartphone giant has remained largely secretive about its progress in semiconductors and AI.
However, over the past two months in April and May 2025, Huawei broke its silence by publishing several detailed research papers outlining the training processes of its large language models (LLMs) using its self-developed Ascend AI chips. This serves as proof that state-of-the-art LLMs can now be trained without relying on GPUs in China.
Pangu Ultra MoE: Scaling Without GPUs
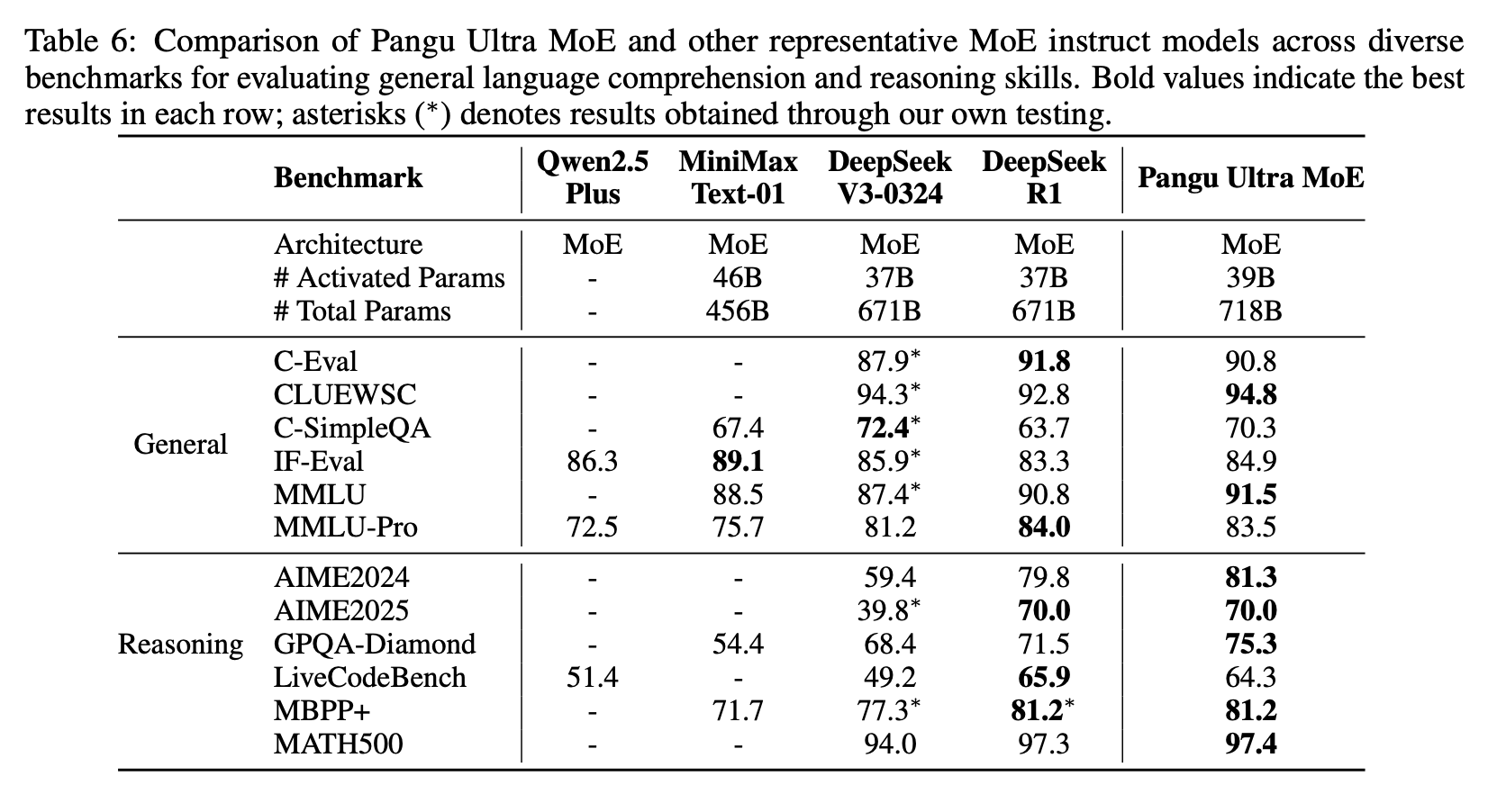
The most eye-catching result is Pangu Ultra MoE, an LLM featuring 718 billion parameters trained using over 6,000 Ascend Neural Processing Units (NPUs).
The model utilizes Mixture-of-Experts (MoE), a popular architecture used in models like GPT-4 and DeepSeek-V3, which routes tasks to specialized sub-models to improve computational efficiency. Specifically, Pangu Ultra MoE employs 256 specialized experts per layer, with only 8 activated per data token at any given moment.
Huawei adopted a simulation-driven method to identify optimal architecture configurations before initiating large-scale training on the 910B platform—Huawei’s older-generation AI chips. Through simulation, researchers accurately modeled throughput, communication, and memory, resulting in a Model-FLOP-Utilization (MFU) of approximately 30%. For comparison, DeepSeek-V3’s MFU ranges from 39% to 44%.
The model architecture closely resembles DeepSeek V3 and R1, incorporating Multi-Head Latent Attention (MLA), which optimizes memory usage by compressing key-value cache space, and Multi-Token Prediction (MTP), which predicts multiple tokens simultaneously to enhance inference efficiency.
To ensure training stability, Huawei introduced two techniques: Depth-Scaled Sandwich-Norm (DSSN), which stabilizes layer outputs through normalization, and TinyInit, a carefully tuned initialization method. Both approaches were also applied to another LLM called Pangu Ultra.
In terms of communication, Huawei implemented hierarchical expert-parallel (EP) strategies combined with adaptive pipeline overlap, reducing communication overhead by roughly 95%. Training followed a “dropless” approach—avoiding token dropping—and used adaptive load balancing to ensure efficiency.
In a separate technical report, Huawei explained how they further improve MoE model training efficiency in three key areas. First, it accelerated computation by optimizing the most time-consuming operations—such as FlashAttention and matrix multiplication—boosting training speed by 15%. Second, it enhanced coordination between its Kunpeng CPUs and Ascend NPUs, minimizing task dispatch delays and adding an additional 4% speedup. Lastly, Huawei addressed memory bottlenecks through a “Selective Recomputation & Swapping” technique, which reduced memory usage by 70%.
Strategic Caution Amid Export Restrictions
Back to chips themselves, starting May 2025, Huawei reportedly began mass-shipping the Ascend 910C—a dual-chiplet upgrade of the 910B—as China’s domestic alternative to Nvidia’s banned H100 chips. Built on SMIC’s 7nm process, it delivers around 800 FP16 TFLOPs. The CloudMatrix 384, Huawei’s rack-scale AI servers that link 384 of these chips, achieves ~300 BF16 PFLOPs—67% more compute than Nvidia’s GB200 NVL72—but consumes nearly four times the power and costs roughly $8.2 million per system.
Meanwhile, the Ascend 920, reportedly unveiled in April 2025 and set for mass production later this year, uses SMIC’s 6nm node and HBM3 memory, promising over 900 BF16 TFLOPs and 30–40% greater efficiency than the 910C. It is aimed squarely at replacing Nvidia’s newly restricted H20 in China.
The Wall Street Journal also reported that the latest 910D—equivalent in performance to three or four existing mature chips—is already under development. (For a deeper look at Huawei’s software and hardware, see the recent analysis by
and .)
In addition to training breakthroughs, Huawei has also presented notable improvements in inference performance using Ascend hardware. For example, on CloudMatrix 384, DeepSeek-R1 can now achieve 1,920 tokens per second per card via decoding, comparable to Nvidia's H100.

Despite the scale of the effort, Huawei remains cautious in its public messaging. In a recent interview, founder Ren Zhengfei said, “The US has made exaggerations about Huawei’s achievements. Huawei is not that good yet,” acknowledging that the company remains one generation behind the U.S. in single-chip performance. “We can still get the results we want by compensating with cluster-based computing,” he added.

The interview coincided with new guidance from the U.S. Commerce Department prohibiting the use of Huawei's Ascend accelerators. According to the agency, these chips were allegedly developed using U.S. technologies without authorization, making their use—commercial or academic—potentially subject to legal penalties.
Nvidia CEO Jensen Huang, in a separate interview, noted that while his company remains ahead of China in chip performance, Huawei could still expand its AI footprint under continued export controls. “AI is a parallel problem, so if each one of the computers is not capable … just add more computers,” he said. “In China, where they have plenty of energy, they’ll just use more chips.”
Huang previous told Bloomberg that Huawei’s latest AI chip is close to the performance of Nvidia’s H200, which features peak performance of 1,979 FP16/BF16 TFLOPS.
A Broader LLM Portfolio
To showcase the breadth of its AI research and hardware capabilities, Huawei previously released several other LLMs targeting diverse applications and performance goals.
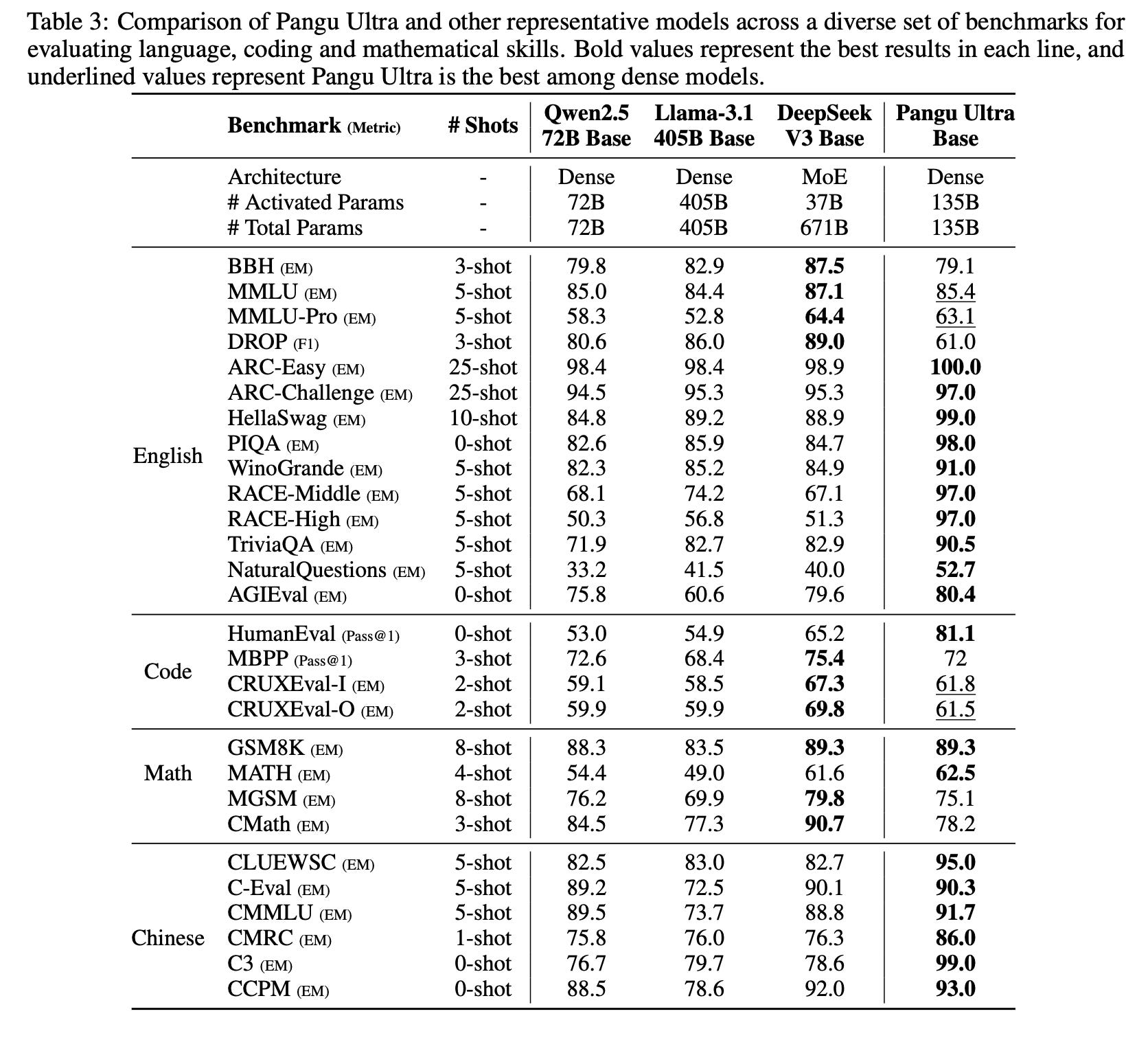
Pangu Ultra, a dense LLM with 135B parameters and a 128K context window, was trained on 13.2 trillion tokens using 8,192 Ascend NPUs. It achieved strong benchmark results, surpassing models such as LLaMA-3 (405B dense), Qwen2.5 (72B), and was competitive with DeepSeek-R1 (671B MoE). Huawei also applied DSSN and TinyInit to help the model achieve over 52% MFU on Ascend chips.
One caveat, however, is that the experimental results of Pangu Ultra are so strong that some have questioned whether the model is overoptimized.
Pangu Pro MoE is a 72B-parameter MoE model (16B active) optimized for Ascend 800I A2 NPUs. Using a Mixture of Grouped Experts (MoGE) strategy, it resolves load imbalance and token latency issues common in MoE models. Pangu-Pro delivers fast inference, achieving 1,528 tokens/sec per card via speculative decoding, and consistently outperforms competitors like Qwen3-32B on reasoning benchmarks.
Pangu Light is Huawei’s structured pruning framework designed to compress large dense models. It applies Cross-Layer Attention Pruning (CLAP) and Stabilized LayerNorm Pruning (SLNP), effectively maintaining performance while significantly reducing model size. The Pangu Light-32B model demonstrates high accuracy (81.6%) and fast throughput (2,585 tokens/sec), surpassing models such as Qwen3-32B.
Pangu Embedded is a 7B-parameter LLM optimized for efficient reasoning on Ascend NPUs. It employs a dual-system cognitive architecture mimicking human thought—fast, intuitive responses, and slow, deliberate reasoning. Through iterative distillation and reinforcement learning, it achieves excellent reasoning performance with minimal latency. Pangu Embedded consistently surpasses similarly sized models in benchmarks and offers flexible user interaction for controlled response complexity.
My Takeaways
Huawei’s chips are often compared with Nvidia’s GPUs based purely on theoretical performance, but it's important to look beyond the numbers and evaluate what these chips can actually deliver.
Huawei’s experiment shows that China can now train near-trillion-parameter LLMs using entirely domestic hardware and software.
This doesn’t signal Nvidia’s imminent irrelevance—Huawei’s chips still lag in power efficiency and ecosystem maturity, and many Chinese tech giants continue to rely on stockpiled Nvidia GPUs. Nvidia’s hardware remains faster and more efficient, which is crucial for rapid model iteration. A recent Wall Street Journal story even described Chinese LLM teams moving data abroad to train with Nvidia chips.
However, the broader implication is clear: export controls alone may no longer be sufficient to prevent China from training world-class LLMs—especially as potential models like GPT-5 have yet to raise the performance ceiling further.
With the H20 now effectively restricted from export to China, Huawei’s research suggests that—even in a worst-case scenario where Nvidia chips are completely cut off—China is able to train frontier models.