
👀DeepSeek’s Next Move: What V4 Will Look Like
Sparsity is DeepSeek's sauce to scale intelligence under hard constraints


The post was originally written at Michael Spencer’s invitation and first published on AI Supremacy here. I have updated and edited it to reflect the latest developments and research.

The widely anticipated DeepSeek V4 model is expected to meet the public this week. V4, DeepSeek’s upcoming generation base model, is supposed to be the largest challenge of open-weight models to the proprietary models, and the most anticipated releases in the AI space for early 2026.
According to Reuters and The Information, DeepSeek V4 is optimized primarily for coding and long-context software engineering tasks. Internal tests (per reporting) suggest V4 could outperform Claude and ChatGPT on long-context coding tasks.

The Financial Times reported that DeepSeek V4 will be a native multimodal model with “picture, video and text-generating functions.” The release would mark a major upgrade from DeepSeek’s previous text-only models, though it comes as little surprise as Chinese AI peers—including Moonshot, Alibaba’s Qwen and ByteDance’s Seed—have already embraced multimodalities in their flagship models.

Tang Jie, co-founder and chief scientist of Chinese AI firm Z.ai, said in an X reply that DeepSeek V4 will likely outperform all existing Chinese open-source LLMs.
Yet from a geopolitical perspective, DeepSeek reportedly withheld its V4 model from U.S. chipmakers including Nvidia and AMD for optimization, instead granting early access to domestic suppliers such as Huawei and Cambricon. The chip access decision reflects a deliberate effort to deepen ties with China’s domestic hardware ecosystem
Last week, Anthropic accused DeepSeek of conducting “distillation attacks” along with two other Chinese AI labs, Moonshot and MiniMax. OpenAI issued a similar accusation against DeepSeek in February. But both accusations drew backlash from the AI community, given that Anthropic, OpenAI, and most of their peers are themselves defendants in copyright and training data lawsuits.
2025 was a watershed moment for DeepSeek and the following open-source movement fueled by Chinese AI labs. The release of DeepSeek V3 base model and R1 reasoning model upended multiple AI narratives: that only spending hundreds of millions could produce a frontier LLM, that only Silicon Valley companies had talents to train competitive models, that the U.S.-China gap in AI was widening due to chip shortages.
Chinese AI labs have also been quick to capitalize on DeepSeek’s openness, adopting its training recipes to slash their own trial-and-error costs while pushing their open models further in knowledge, reasoning, and agentic coding.
Throughout the rest of 2025, DeepSeek continued churning out models with incremental improvements, including DeepSeek-V3.2-Thinking and DeepSeek-Math-V2, which won the International Olympiad in Informatics. Yet the widely anticipated DeepSeek-V4 and DeepSeek-R2, which were reportedly slated for release in the first half of 2025, were delayed. According to reports, DeepSeek CEO Liang Wenfeng was dissatisfied with the results and chose to delay the launch.
The Financial Times offered an alternative explanation: DeepSeek initially attempted to train R2 using Huawei’s Ascend AI chips rather than Western silicon like Nvidia’s GPUs, partly due to pressure from the Chinese government to reduce reliance on U.S.-made hardware. The training runs encountered repeated failures and performance issues stemming from stability problems, slow chip-to-chip interconnect speeds, and immature software tooling for Huawei’s chips. Ultimately, DeepSeek had to revert to Nvidia hardware for training while relegating Huawei chips to inference tasks only. This back-and-forth process and subsequent re-engineering significantly delayed the timeline.

Sparsity Through Iteration
DeepSeek’s architectural evolution has been driven by a consistent principle: Sparsity.
While computation can be scaled relatively easily by adding more data, more parameters of the model, and more chips, sparsity is the most straightforward way DeepSeek can scale intelligence under constraints, including compute, memory bandwidth, and chips. These constraints shaped every iteration of their model architecture, from DeepSeekMoE’s initial Mixture of Experts (MoE) through the attention optimizations in V2, V3, and V3.2.
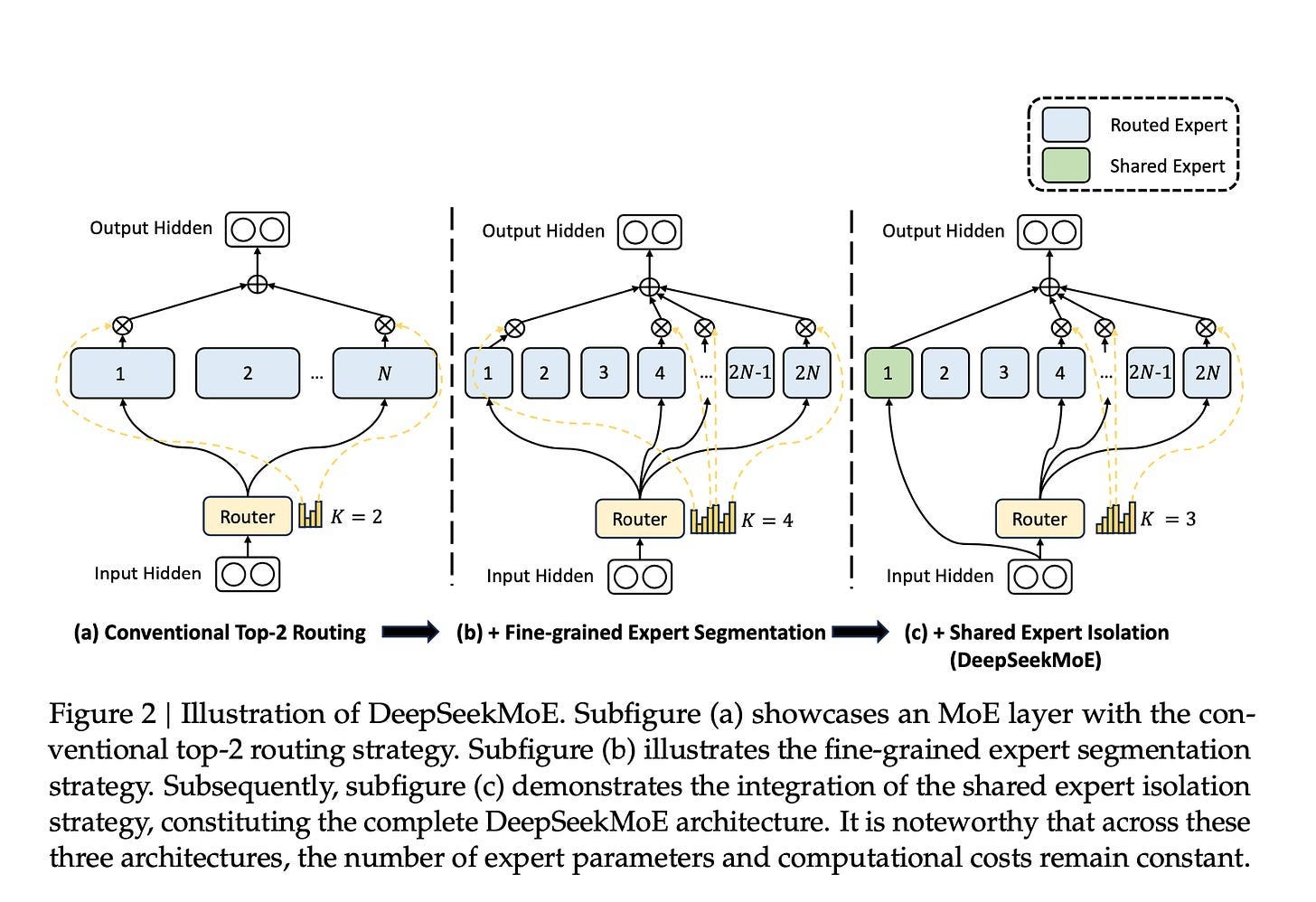
In a Transformer, you have two main computational blocks: Attention and Network (specifically Feed-Forward Network). DeepSeek started by making the network layers sparse using MoE. Instead of every token going through the entire network, they route each token to only a small, relevant subset of parameters as experts.
DeepSeekMoE laid the groundwork with a MoE architecture containing 64 specialized experts and 2 shared experts. For each input, the model would route it to the 6 most relevant experts (topk=6).
DeepSeek-V2 expanded the expert pool to 160 specialized experts while keeping 2 shared experts and the same topk=6 routing, with improvements focused on distribution and efficiency.
DeepSeek-V3 scaled further to 256 experts with 1 shared expert, and increased routing to topk=8. The architecture became more sophisticated in how it managed experts, and introduced a new communication system called DeepEP that makes expert coordination more efficient.
Once the network sparsity was well-optimized, attention became the next target for improvement. As the core module of the Transformer architecture, attention is where each token in a sequence analyzes and weights the importance of every other token to understand context and relationships. Attention presents a different challenge as computational complexity exponentially grows along with the increasing context window.
Multi-head Latent Attention (MLA) was DeepSeek’s first major attention innovation introduced in V2. Instead of storing complete key-value information for every token (as standard Multi-Head Attention does), MLA compresses this information into a smaller representation. This compression reduces how much data needs to be moved in and out of memory.
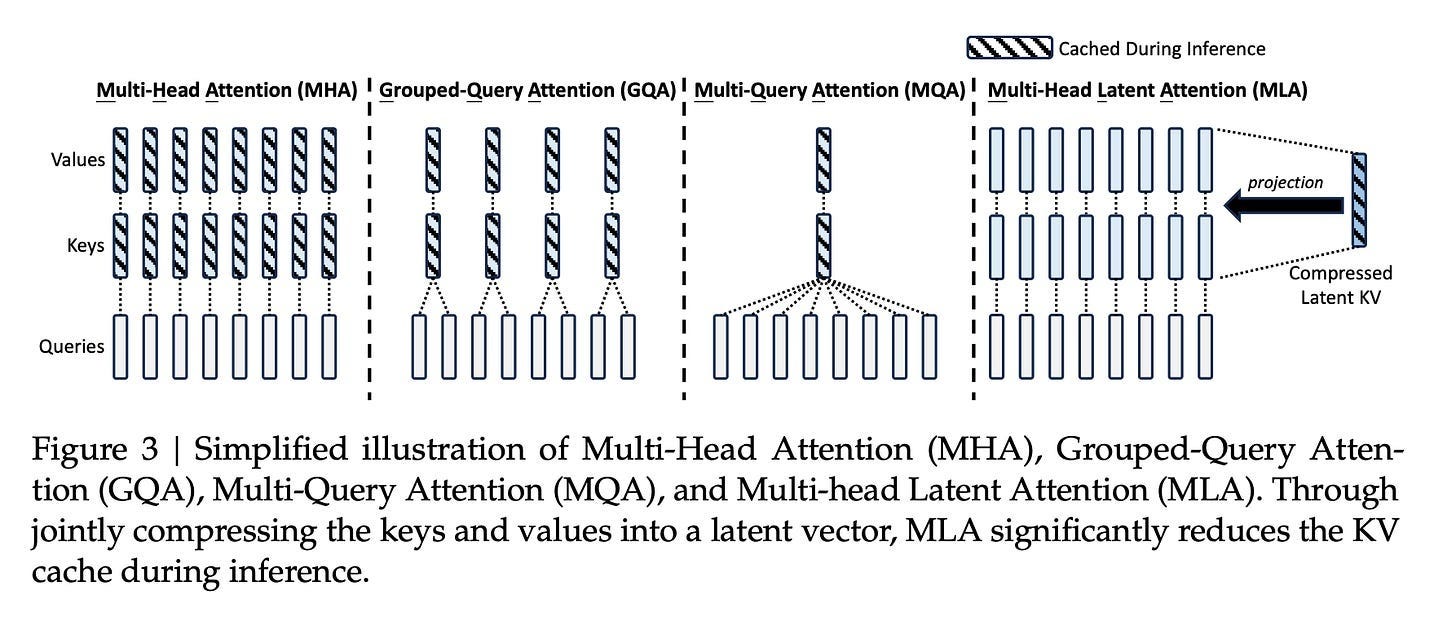
Then in a February 2025 paper, DeepSeek introduced Native Sparse Attention (NSA) with optimized design for modern hardware. Tokens are processed through three attention paths: compressed coarse-grained tokens, selectively retained fine-grained tokens, and sliding windows for local contextual information.

DeepSeek Sparse Attention (DSA), introduced in V3.1 and V3.2, streamlined the NSA design. Instead of selecting blocks of tokens, DSA selects individual tokens. It uses a lightweight indexer model to identify the 2,048 most relevant tokens from the full context. This indexer is trained through a process where it learns to mimic the full attention pattern—the model first trains with full attention, then the indexer learns to predict which tokens the full attention would focus on. DSA can work with MLA.

Multimodality Signals in DeepSeek OCR 2
The Financial Times’ reporting on DeepSeek V4’s multimodalities reminds me of DeepSeek’s important research in visual understanding, notably DeepSeek OCR.
Last year, I wrote about DeepSeek OCR, an innovative vision-language model that compresses long texts into visual tokens by 7 to 20 times, potentially enabling LLMs to process lengthy documents more efficiently. DeepSeek OCR consists of two main components:
DeepEncoder is a custom encoder that combines SAM-base (window attention) with CLIP-large (dense global attention), plus a 16× token compressor. It offers controllable resolution modes (Tiny/Small/Base/Large/Gundam/Gundam-M).
The LLM is a 3B MoE model with ~570M activated parameters at inference (6 out of 64 routed experts plus 2 shared experts).

In January, DeepSeek upgraded the model to DeepSeek OCR 2. The core improvement in DeepSeek OCR 2 is a new visual encoder called DeepEncoder V2, which introduces a concept called visual causal flow.
Traditional vision-language models read images in a fixed raster order (top-left → bottom-right).
DeepEncoder V2 instead reorders visual tokens based on semantic structure, mimicking how humans scan documents.
This enables better reasoning over complex layouts such as multi-column papers or tables.
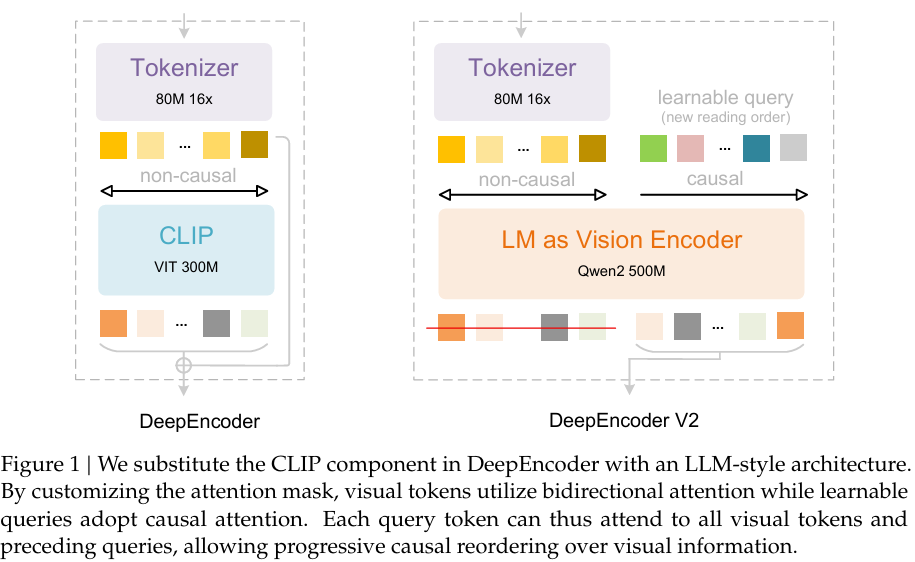
It’s worth noting that in the paper, DeepSeek researchers said
DeepEncoder V2 provides initial validation of the LLM-style encoder’s viability for visual tasks. More importantly, this architecture enjoys the potential to evolve into a unified omni-modal encoder: a single encoder with shared 𝑊𝑘,𝑊𝑣 projections, attention mechanisms, and FFNs can process multiple modalities through modality-specific learnable query embeddings. Such an encoder could compress text, extract speech features, and reorganize visual content within the same parameter space, differing only in the learned weights of their query embeddings. DeepSeek-OCR’s optical compression represents an initial exploration toward native multimodality, while we believe DeepSeek-OCR 2’s LLM-style encoder architecture marks our further step in this direction. We will also continue exploring the integration of additional modalities through this shared encoder framework in the future
DSA+mHC+Engram
With the foundation of DSA established in V3.2, DeepSeek appears ready to push optimization further in V4. The evidence points to two other papers that DeepSeek released over the past few months.
Manifold-Constrained Hyper-Connections (mHC)
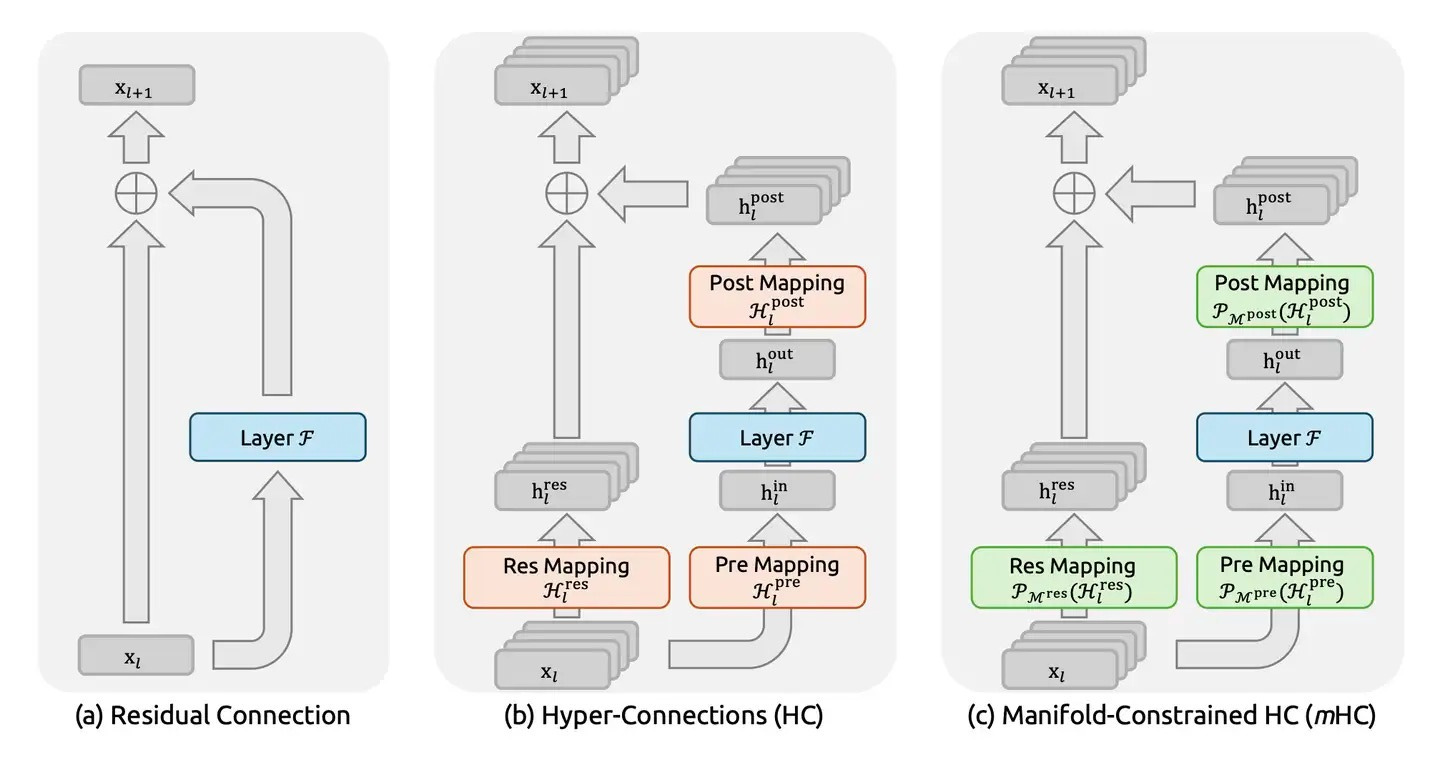
mHC represents a rethinking of how information flows through deep neural networks. While traditional networks pass information sequentially from one layer to the next, mHC introduces richer connectivity patterns between layers—essentially creating multiple pathways for information to flow across the model’s depth.
To understand mHC’s, we must first revisit residual connections, the backbone of modern deep neural networks regardless of architecture (CNN or Transformer). Proposed in the landmark 2015 paper Deep Residual Learning for Image Recognition, residual connections add the input (x) of a block directly to its output F(x), typically formatted as y = F(x) + x.
This simple shortcut proved revolutionary. By allowing gradients to bypass layers, residual connections solved the vanishing gradient problem that had plagued deep networks, enabling effective training of architectures with hundreds or even thousands of layers.
Then in 2024, ByteDance researchers proposed hyper-connections (HC) as an alternative approach. Rather than simple additive shortcuts, HC creates richer connectivity patterns that allow information to flow more freely between non-adjacent layers. This architectural flexibility offers advantages over standard residual connections, particularly in avoiding the gradient-representation tradeoffs.
But HC introduced its own challenge. As training scales increase and connectivity grows richer, the risk of training instability rises. More pathways for information flow means more opportunities for gradients to either explode (grow uncontrollably large) or vanish (shrink to near-zero) during training.
This is where DeepSeek mHC’s innovation emerges. The approach treats the model’s parameter space as existing on a high-dimensional geometric structure, a manifold. By imposing mathematical constraints based on this manifold geometry, mHC creates a guardrail system that maintains stable information flow even as connectivity increases.
Think of it as a multi-lane highway with intersections. Vehicles can change lanes, merge, or split—increasing routing flexibility. But the total traffic flow must remain constant and balanced. Information can take different paths through the network, but the overall flow is constrained to prevent either congestion (gradient explosion) or emptiness (gradient vanishing).
The mathematical formulation ensures that information transformations remain well-behaved across the manifold. This prevents the instabilities that would otherwise emerge from unconstrained hyper-connections, enabling deeper and more flexible architectures while maintaining training stability.
For V4, mHC could appear strategic. As DeepSeek pushes toward increasingly sparse and selective processing through DSA, Engram, and other mechanisms, having stable hyper-connections allows these components to interact more effectively across layers.
Engram
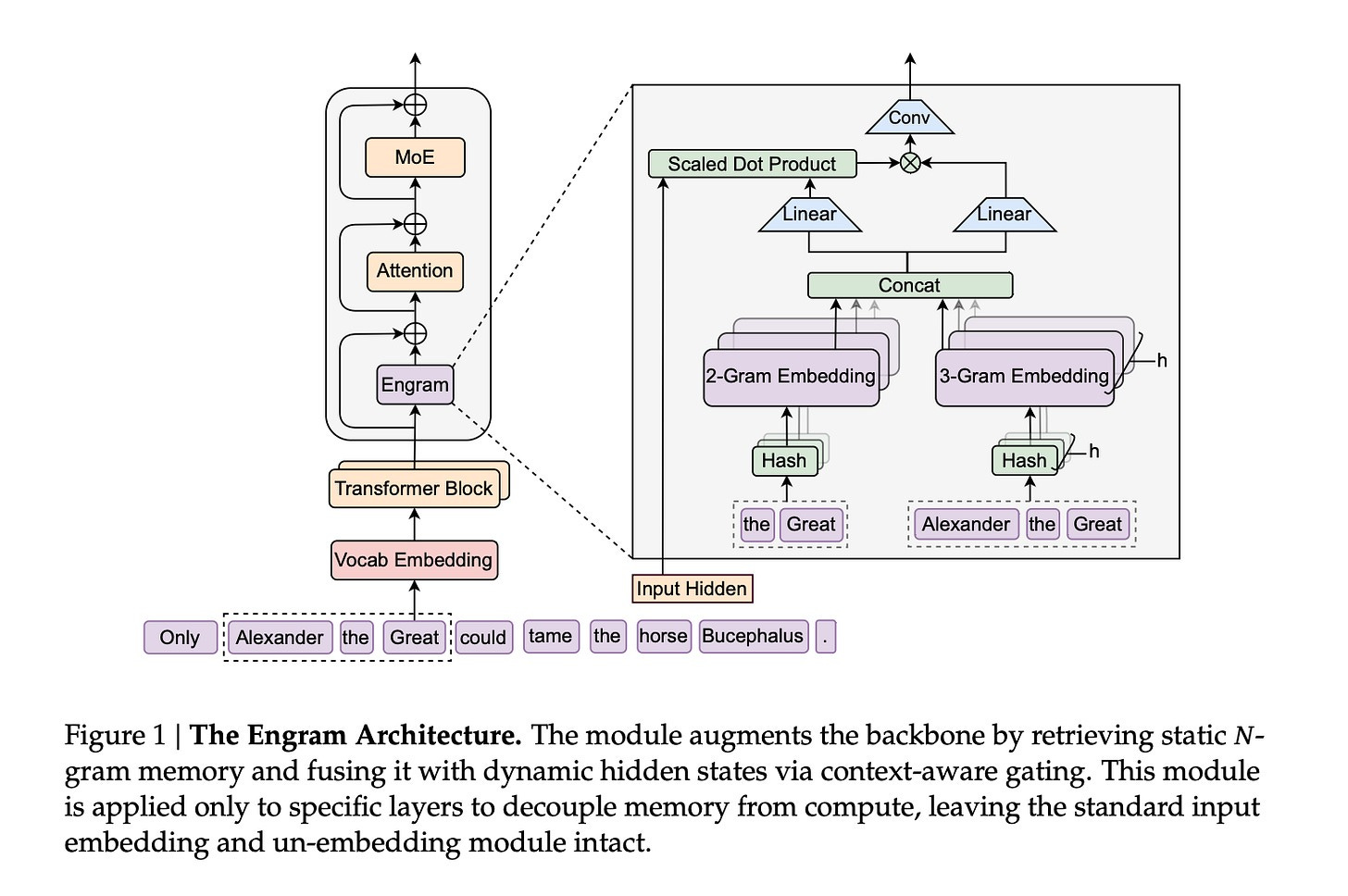
Engram, detailed in DeepSeek’s January 2026 paper Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models, introduces a new dimension to model architecture by adding conditional memory to the Transformer through efficient lookup mechanisms.
Traditional Transformer-based LLMs compress all learned knowledge into neural network weights. Whether answering a simple factual query like “Barack Obama was a U.S. president” or solving a complex mathematical proof, the model must route every computation through the same expensive neural processing.
Consider the phrase “New York City.” A standard Transformer must learn that “New,” “York,” and “City” together form a specific entity, then rebuild that relationship through attention computation every single time. This is static knowledge that never changes, yet the model treats it like novel information requiring full neural processing each time.
Engram’s premise is elegantly simple: not all knowledge requires neural computation. Static facts and established patterns can be stored in a complementary memory system and retrieved efficiently when needed. This mirrors biological memory: You don’t re-calculate that 2+2=4 each time; you simply recall it.
Engram implements this through a modernized N-gram lookup module operating in constant time (O(1))—retrieval speed remains constant regardless of how much information is stored. This creates a fundamental architectural separation:
Neural computation (attention and MoE): Complex reasoning, novel synthesis, context-dependent processing
Memory lookup (Engram): Static knowledge, established patterns, factual recall
The architecture optimizes the balance using a U-shaped scaling law—a mathematical framework determining ideal parameter allocation between neural computation and memory lookup at different model scales. This is crucial because the tradeoff isn’t straightforward: too much reliance on lookup tables risks brittleness; too much neural computation wastes resources on static knowledge. The U-shaped law identifies the sweet spot where both systems work synergistically.
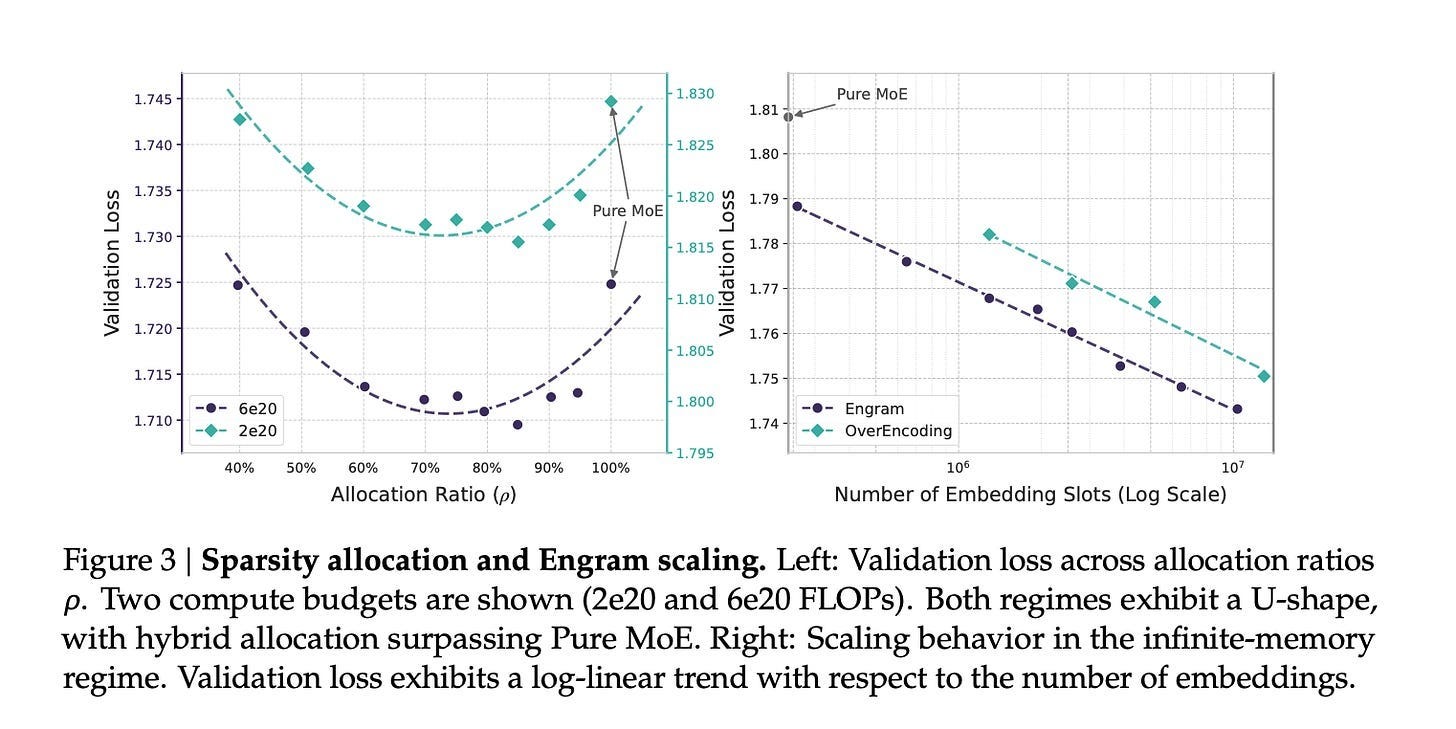
Memory efficiency improves dramatically because Engram offloads static knowledge from expensive GPU memory to host CPU memory. Empirical results demonstrate that offloading a 100B-parameter lookup table to host memory incurs negligible overhead (less than 3%). This enables massive knowledge bases without proportional GPU memory costs, while supporting much longer effective context windows.
For reasoning and knowledge-intensive tasks, Engram delivers measurable improvements over comparable MoE-only architectures. Benchmarks show particular gains in multi-hop reasoning and long-context understanding—tasks that benefit from quick access to established knowledge while applying neural computation to novel reasoning steps.
Just before the release of this blog, DeepSeek, Peking University, and Tsinghua University introduced DualPath. The system aims to solve a massive I/O bottleneck in long-context agentic inference. Since decoding engines often sit idle while prefill engines are overwhelmed moving KVcache from storage, DualPath uses those idle engines to load the cache and transfer it to the prefill engines via RDMA. DualPath improves offline inference throughput by up to 1.87x and online inference by 1.96x. I see no reason why DualPath wouldn’t be incorporated into DeepSeek V4’s inference.

Model1: New Clues to DeepSeek V4?
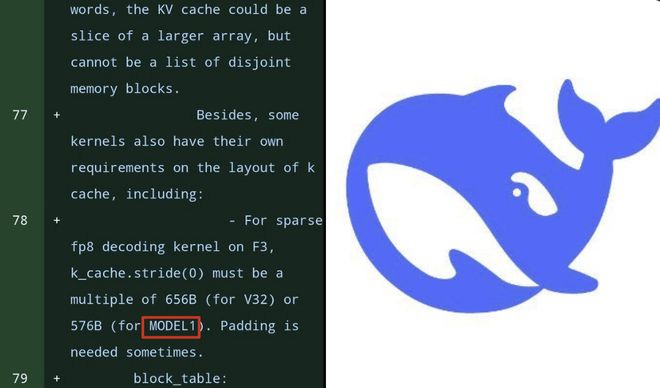
Just over a year after DeepSeek-R1 became the most-liked model on Hugging Face, sharp-eyed developers have spotted a mysterious “Model1” in recent code updates to the FlashMLA library. The timing is suggestive—could Model1 be the codename for DeepSeek V4?
Analysis of recent commits reveals several architectural signatures suggesting Model1 is an entirely new flagship model:
The 512-Dimensional Shift: Model1 switches from V3.2’s 576-dimensional configuration to 512 dimensions, likely optimizing for NVIDIA’s Blackwell (SM100) architecture where power-of-2 dimensions align better with hardware.
Blackwell GPU Optimization: New SM100-specific interfaces, CUDA 12.9 requirement, and performance benchmarks showing 350 TFlops on B200 for sparse MLA operations represent deep integration with next-generation hardware.
Token-Level Sparse MLA: Separate test scripts for sparse and dense decoding indicate parallel processing pathways. The implementation uses FP8 for storing KV cache and bfloat16 for matrix multiplication, suggesting design for extreme long-context scenarios.
Value Vector Position Awareness (VVPA): This new VVPA mechanism likely addresses a known weakness in traditional MLA—positional information decay over long contexts. As sequences extend into hundreds of thousands of tokens, compressed representations can lose fine-grained positional details. VVPA appears designed to preserve this spatial information even under aggressive compression.
Engram Integration: References to Engram throughout the codebase suggest deep integration into Model1’s architecture.
I believe V4 and R2 will remain among the best open-source LLMs available, potentially even narrowing the gap with leading proprietary models. However, since DeepSeek R1’s release over a year ago, the competitive race to push LLM capabilities forward has only intensified. The “DeepSeek effect” has motivated several other Chinese AI labs—including Moonshot AI, MiniMax, and Zhipu—to redouble their efforts in releasing top-tier LLMs. This doesn’t even account for tech giants Alibaba and ByteDance, both of which are producing frontier models while simultaneously expanding into chatbots, AI cloud services, chips, and hardware.
Given this rapidly evolving landscape, expecting another watershed “DeepSeek moment” like the one in early 2025 seems nearly impossible.
The progression from 64 to 160 to 256 experts is interesting to track. DeepSeek keeps scaling the expert count while NVIDIA took a different route with Nemotron 3 Super; 512 experts but only 22 active per token, and they compress tokens into a lower-dimensional latent space before routing. LatentMoE they call it. Gets you 4x more experts at the same compute cost.
Both are betting on sparsity but the mechanisms diverge pretty sharply. DeepSeek's MLA and native sparse attention attack the KV cache bottleneck. Nemotron stacks Mamba-2 layers (linear cost) with sparse attention layers and routes through LatentMoE. I covered the Nemotron architecture in detail here https://reading.sh/inside-the-model-merging-three-ai-architectures-into-one-c5dcc7302528 and the 10:1 total-to-active parameter ratio is the part that keeps surprising people.
Curious whether V4 will stick with pure transformer + MoE or if they'll follow the hybrid trend. Qwen 3.5 went GDN, Nemotron went Mamba, IBM Granite went hybrid too. Feels like pure transformers are losing ground.