
👀DeepSeek Reveals New Training Method Ahead of DeepSeek-R2 Release
DeepSeek and Tsinghua University researchers introduce Self-Principled Critique Tuning, a method for training reward models that may guide DeepSeek-R2 toward stronger performance in general domains.


Hi, this is Tony! Welcome to this issue of Recode China AI (for the week of March 31, 2025), your go-to newsletter for the latest AI news and research in China.
In this post, I’ll briefly explore DeepSeek’s latest paper, Inference-Time Scaling for Generalist Reward Modeling, published ahead of the rumored release of DeepSeek-R2.
The paper is fascinating: it introduces a new training method for reward model—a key component in reinforcement learning (RL) that scores LLM answers and helps guide them toward better performance—that can generate its own scoring criteria and then critique how well each response follows those guidelines. The researchers applied test-time compute to training the reward model by scaling up the generation of evaluation criteria and critiques, which led to more accurate and reliable reward models.
If I’m not mistaken, this reward model is likely used to guide DeepSeek-R2. According to the paper, it can boost the model’s reasoning abilities in general domains, not just in math and coding. Personally, I think this paper is essential reading for anyone looking to understand how DeepSeek is training its next-generation reasoning LLM.
What’s New: Researchers from DeepSeek and Tsinghua University introduced a new AI training technique likely behind DeepSeek’s next-generation reasoning model, DeepSeek-R2, rumored for release in May.
The new method, called Self-Principled Critique Tuning (SPCT), trains a reward model—think of it as an AI judge—to both create its own judging criteria (principles) and critique responses generated by large language models (LLMs). Experiments show the SPCT-trained model, DeepSeek-GRM, outperformed GPT-4o in reward model benchmarks.
Why It Matters: Reinforcement Learning (RL) has already been proven effective in improving the reasoning abilities of LLMs, particularly in structured tasks like math and coding. Models such as OpenAI’s o1 and DeepSeek-R1 showed significant improvements in these areas. However, for broader tasks—like casual conversations, factual queries, creative writing, or safety-related questions—it's unclear how to reliably measure whether a response is good.
This research aims to create a generalist reward model capable of accurately evaluating LLM-generated answers across general topics in the RL-driven post-training process, eventually guiding the LLM toward improved performance. If successful, it could greatly expand the practical application of LLMs across industries by improving their reasoning in more general situations.
How it Works: Researchers tested various types of reward models—pairwise, pointwise, scalar, generative—and found that Pointwise Generative Reward Modeling (GRM) was the most flexible. Such model produces both a detailed critique (an explanation) and a numeric score for each answer. It’s like a teacher giving detailed feedback on your essay, rather than just assigning a grade like “B+” or “C−,” or merely picking the better one from two responses.. Unlike pairwise or scalar methods, pointwise GRM can independently assess multiple responses.

Next, the researchers explored if setting clear principles (judging criteria) would improve reward quality. These principles cover factors such as detail, safety, accuracy, or completeness. The study confirmed that using proper principles can improve the quality of evaluations.
The researchers made a key assumption:
Inference-time scalability of RM might be achieved by scaling the generation of high-quality principles and accurate critiques.
Simply put, if you let the reward model generate more sets of principles and critiques during test (inference) time, you can scale up the model’s ability to give better, more reliable scores—much like having multiple judges.
Inspired by these findings, the team proposed SPCT. Before giving scores or critiques, the reward model first explicitly devised the principles it will use, and then adapted them based on the specific question asked. This makes sense, since the criteria for evaluating a casual conversation should differ from those used for medical questions, for example.
SPCT training involves two stages:
Rejective fine-tuning: The model is trained to predict correct scores on many question–answer sets, rejecting any of the model’s attempts that get the score wrong.
Rule-based online reinforcement learning: The model generates principles and critiques repeatedly; whenever it rates answers correctly, it gets a small reward signal, pushing it to refine these “self-principled” judging criteria.
To further improve the reward model, researchers applied the test-time compute by using sampling-based strategies to scale the generations of the reward model. The model can run a large number of evaluations, each potentially producing different principles and critiques. Aggregating these results (such as by majority voting) further enhances accuracy. Additionally, the team introduced a “meta” reward model that automatically filters out weaker critiques, further boosting reliability.

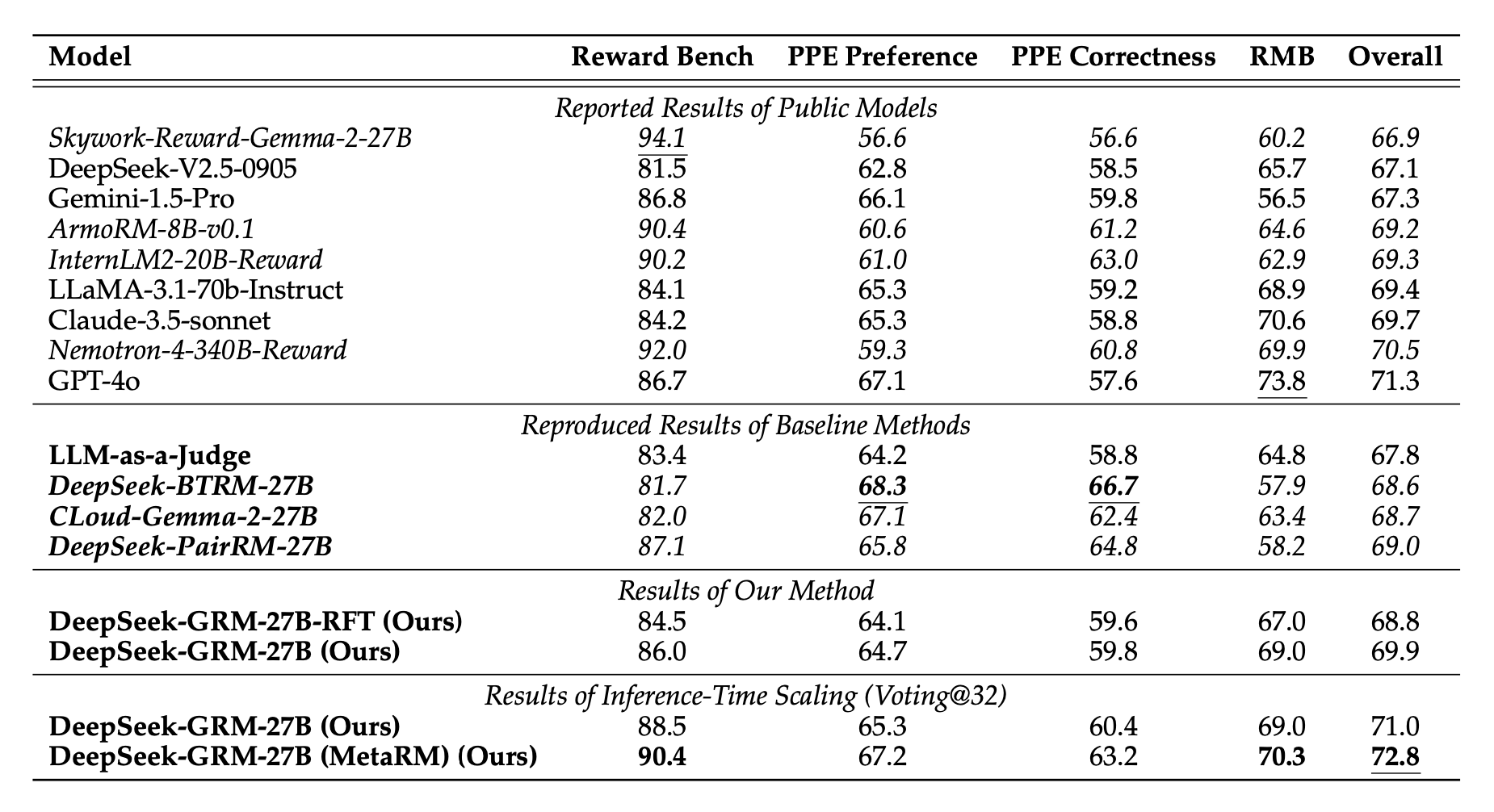
DeepSeek-GRM performs strongly across several evaluation sets for reward models. DeepSeek-GRM-27B achieved an impressive overall accuracy score of 69.9%. By generating and aggregating multiple critiques (32 rounds of voting), accuracy improved further to 71.0%. When using the “meta” filter (MetaRM), accuracy climbed to 72.8%.
Importantly, this model demonstrates less bias and improved handling of diverse questions—covering facts, logical reasoning, and subjective assessments—compared to traditional scalar reward models.