
🔥DeepSeek-R1 and Kimi k1.5: How Chinese AI Labs Are Closing the Gap with OpenAI’s o1
Two prominent Chinese AI startups, DeepSeek and Moonshot AI, unveiled reasoning models that rival OpenAI’s o1, and shared insights into large-scale reinforcement learning for training LLMs.


Hi, this is Tony! Welcome to this issue of Recode China AI (for the week of January 20, 2025), your go-to newsletter for the latest AI news and research in China.
What’s new this week? DeepSeek, the buzzy Chinese AI lab, officially open-sourced DeepSeek-R1 this week, a series of reasoning LLMs designed to think step-by-step before answering and excel in reasoning-intensive tasks like math and coding. The release includes DeepSeek-R1-Zero, an advanced DeepSeek-R1 that rivals OpenAI’s o1 reasoning model, along with several smaller dense models.
Meanwhile, Moonshot AI, a $3.3 billion-valued Alibaba-backed AI startup, introduced Kimi k1.5, a multimodal reasoning LLM that also matches o1 on math tasks.
OpenAI’s o1, DeepSeek-R1 and Kimi k1.5 represent a paradigm shift known as test-time compute, which refers to the computational resources utilized during inference. This is distinct from the pre-training phase, where the model learns from massive data. As AI masterminds like Ilya Sutskever predict that pre-training may plateau due to the diminishing availability of public data, the test-time compute paradigm offers an alternative path for extending scaling laws and continuing AI advances.
While in the U.S., only a few players like Anthropic and Google developed reasoning LLMs, Chinese companies have rapidly and more aggressively embraced this technology. In just four months since o1’s debut in September, nearly 10 Chinese firms have released similar models, including Alibaba’s QwQ and Marco-o1, Zhipu AI’s GLM-Zero, Shanghai AI Lab’s InternThinker, iFlyTek’s X1, and Skywork’s Skywork-o1.
This article will dive into the innovations behind DeepSeek-R1 and Kimi k1.5 and explore why Chinese companies are following up so quickly.
A Deep Dive into DeepSeek-R1/R1-Zero

The DeepSeek-R1 paper highlights two major innovations. First, they applied reinforcement learning (RL) directly to the base model without relying on supervised fine-tuning (SFT) as a preliminary step. It’s like a student skipping the class and going straight to practicing through trial and error. This also marks the first open research to demonstrate that LLMs can develop robust reasoning abilities through RL alone.
The model reminds me of AlphaZero, developed by Google DeepMind in 2017, which achieved superhuman performance in games like Go, chess, and shogi by learning solely through self-play without human data.
As a result, DeepSeek-R1-Zero matched an earlier version of OpenAI’s o1 on math but lagged in coding.
It also yielded several noteworthy findings. For example, the model can think longer throughout the RL training process. The increasing test-time compute also leads to emergent behaviors, such as reflection and the exploration of alternative problem-solving approaches. Another surprising “aha moment” was that DeepSeek-R1-Zero learned to allocate more time to thinking by reevaluating its initial problem-solving strategy.

While pure RL offers advantages, it suffers from limitations like poor readability and language mixing. To address these, the team developed DeepSeek-R1.
The training process of DeepSeek-R1 consists of four stages.
Fine-tuning the base model (DeepSeek-V3) with a small dataset of long chain-of-thought (CoT) data.
Applying RL to boost reasoning in areas like math and coding.
Using this model to curate 600k reasoning data samples, along with another 200K non-reasoning samples, to retrain the base model for general capabilities.
Aligning the fine-tuned model with human preferences using RL. The training process is illustrated below, credit to Google’s Harris Chan.

DeepSeek-R1 achieved 90.8 on the MMLU benchmark, slightly below o1 but surpassing GPT-4o and Claude-3.5-Sonnet. On AIME and MATH benchmarks, R1 outperformed o1 by scoring 79.8 and 97.4 respectively, However, its coding performance remains slightly inferior to o1. Surprisingly, R1 also performed well on non-reasoning tasks such as creative writing, editing, summarization, and more.
Secondly, the researchers demonstrated that the reasoning abilities of larger models can be distilled into smaller models. Distilled models without RL training perform better than small models trained through RL alone. Using Qwen and Llama models for their experiments, they distilled reasoning data from DeepSeek-R1. The results were impressive: DeepSeek-R1-Distill-Qwen-7B outperformed non-reasoning models like GPT-4o-0513 across the board. DeepSeek-R1-32B and DeepSeek-R1-70B significantly outperformed o1-mini on most benchmarks.

One of DeepSeek’s key advantages is its competitive pricing, and R1 is no exception. DeepSeek-R1 costs $0.14 per million input tokens (cache hit), $0.55 per million input tokens (cache miss), and $2.19 per million output tokens. In comparison, o1 charges $15.00 per million input tokens and $60.00 per million output tokens.

Open-sourced under an MIT license, DeepSeek-R1 can be utilized, modified, and distributed for free with minimal restrictions.
Inside Kimi k1.5, A Multimodal Reasoning Model
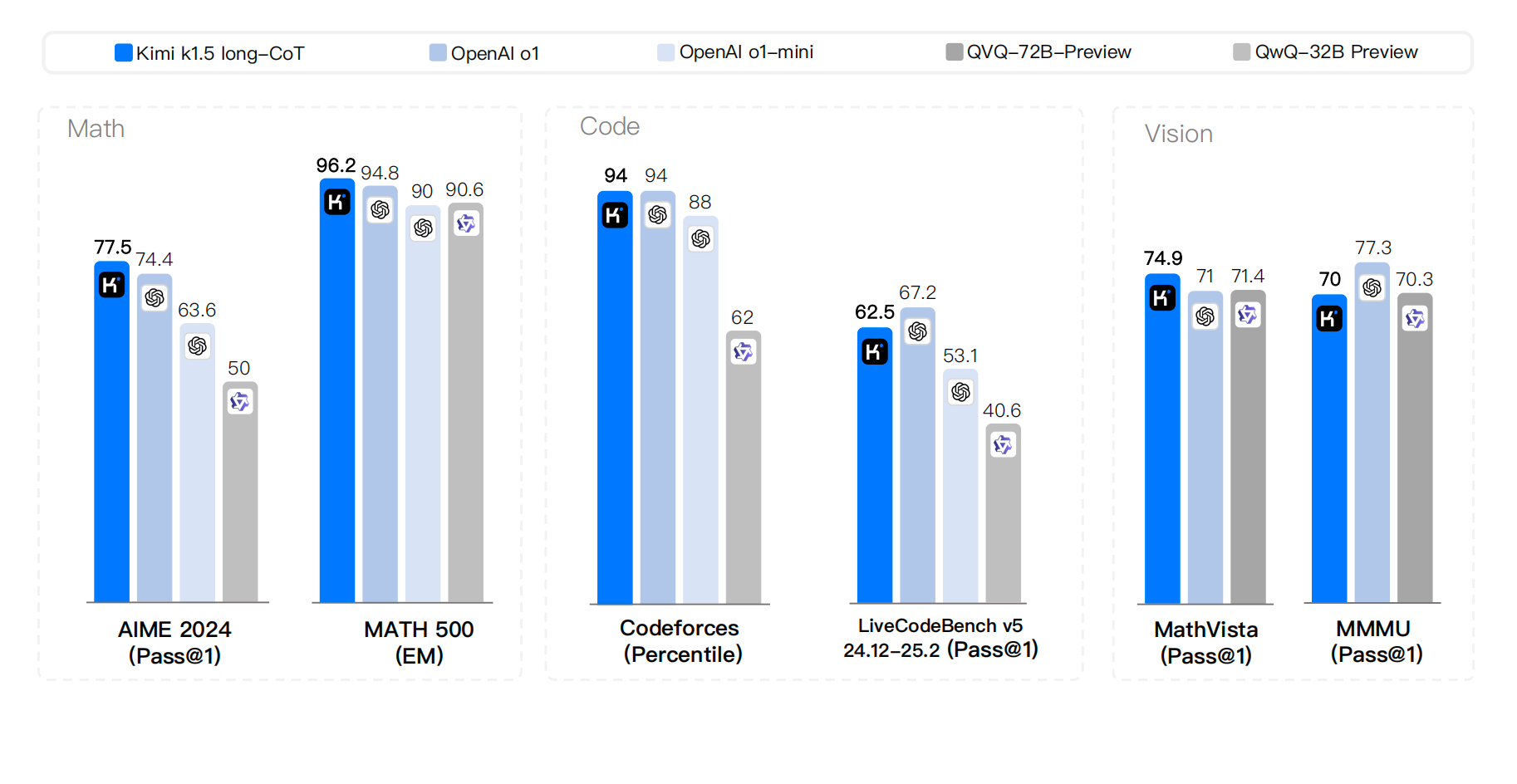
The k1.5 technical report highlights three key contributions.
First, the researchers scaled the RL context window to 128k tokens, and observed continuous performance improvements as the context length increased. This innovation builds on Moonshot AI’s expertise, as the company’s previous LLMs are known for their long context window.
Second, they combined various techniques to enhance RL policy optimization. The paper provides more details of training techniques then the DeepSeek paper. In short, by integrating long context scaling with improved policy optimization, they achieved strong performance without relying on more complex methods like Monte Carlo Tree Search (MCTS), value functions, or process reward models (PRM).
As a result, Kimi k1.5 delivered SOTA reasoning performance across multiple benchmarks and modalities – 77.5 on AIME, 96.2 on MATH 500, and placing in the 94th percentile on Codeforces. While its performance lagged behind DeepSeek-R1, many attribute this to DeepSeek’s more advanced base model, DeepSeek-V3. k1.5 also excels in multimodal reasoning tasks such as MathVista, which require visual comprehension of geometry, IQ tests, and more.
Third, the report also introduced effective long2short methods that use long-CoT techniques to train short-CoT models. While long-CoT enables the model to spend more time thinking before answering, which results in higher-quality responses, it comes at a high computational cost. Short-CoT models address this by significantly reducing inference costs. As a result, Kimi k1.5’s short-CoT model outperformed other short-CoT models like GPT-4o and Claude Sonnet 3.5 by a wide margin.
Overall, the two papers, released around the same time, share similar findings. For example, both observed that as training progresses, response length and performance accuracy improve. Neither relies on complex techniques like MCTS, value functions, or PRM.
Why Chinese Companies Are Catching Up So Fast
When OpenAI released GPT-4, it took Chinese AI labs 12 to 18 months to develop similar LLMs with closely matched performance. However, just two months after OpenAI unveiled o1, DeepSeek previewed its R1 model in November 2024. The speed of catching up is accelerating.
One reason is that while OpenAI’s o1 is considered groundbreaking, replicating an o1-style reasoning model is not overly complex. One method is the above-mentioned RL, which trains LLMs by simulating a step-by-step thought process and optimizing their responses through trial and error. This approach rewards the model for accurate and well-structured outputs.
Another simpler approach is distillation, a technique that transfers the knowledge from a superior model to a smaller model. A recent paper from Shanghai Jiao Tong University showed that fine-tuning a base model on tens of thousands of o1-distilled examples can outperform o1-preview on benchmarks like AIME. MiniMax CEO Yan Junjie also said it’s not difficult to replicate something akin to o1 by distilling a few thousand data samples. However, he warned that this approach has limitations.
In fact, there has always been an alignment tax in text models, that is, if you must align the model with another model, such as the results of GPT, there will be some limitations on capabilities.
Even without distillation or RL, powerful reasoning models can still be built. For instance, rStar-Math from Microsoft demonstrated that small language models (SLMs) can rival or surpass o1’s math reasoning capabilities using MCTS.
Additionally, test-time compute research is relatively affordable compared to pre-training, which requires extensive resources. This affordability makes it attractive for Chinese labs, especially under export controls that limit access to advanced AI chips.
The big picture is the Chinese AI labs are narrowing the gap with their U.S. counterparts. They are good at rapidly adopting and building on proven technologies. Once a direction in AI research is validated as effective, they can efficiently implement it and use their engineering strengths to deliver competitive or even superior results while using fewer resources. Beyond reasoning models. DeepSeek-V3 and Qwen-2.5 are considered the SOTA LLMs, while video generators from China’s Kuaishou and MiniMax pose new competition for OpenAI’s Sora.
Chinese AI companies are also increasingly open sourcing their models and tools, another factor driving their AI development. The momentum is growing, with even closed-source companies like Tencent and MiniMax now open-sourcing their video generator HunyuanVideo and LLM MiniMax-01.
But some Chinese researchers are determined to shed the label of imitators or copycats. True innovation is the only path to catching up. While it may come with higher failure rates and costs, it is absolutely necessary. As DeepSeek CEO Liang Wenfeng said in an interview:
What we see is that Chinese AI cannot be followers forever. We often say that Chinese AI lags behind the U.S. by one or two years, but the real gap lies in the difference between innovation and imitation. If this doesn’t change, China will always be a follower. Some forms of exploration are therefore inevitable.
Weekly News Roundup
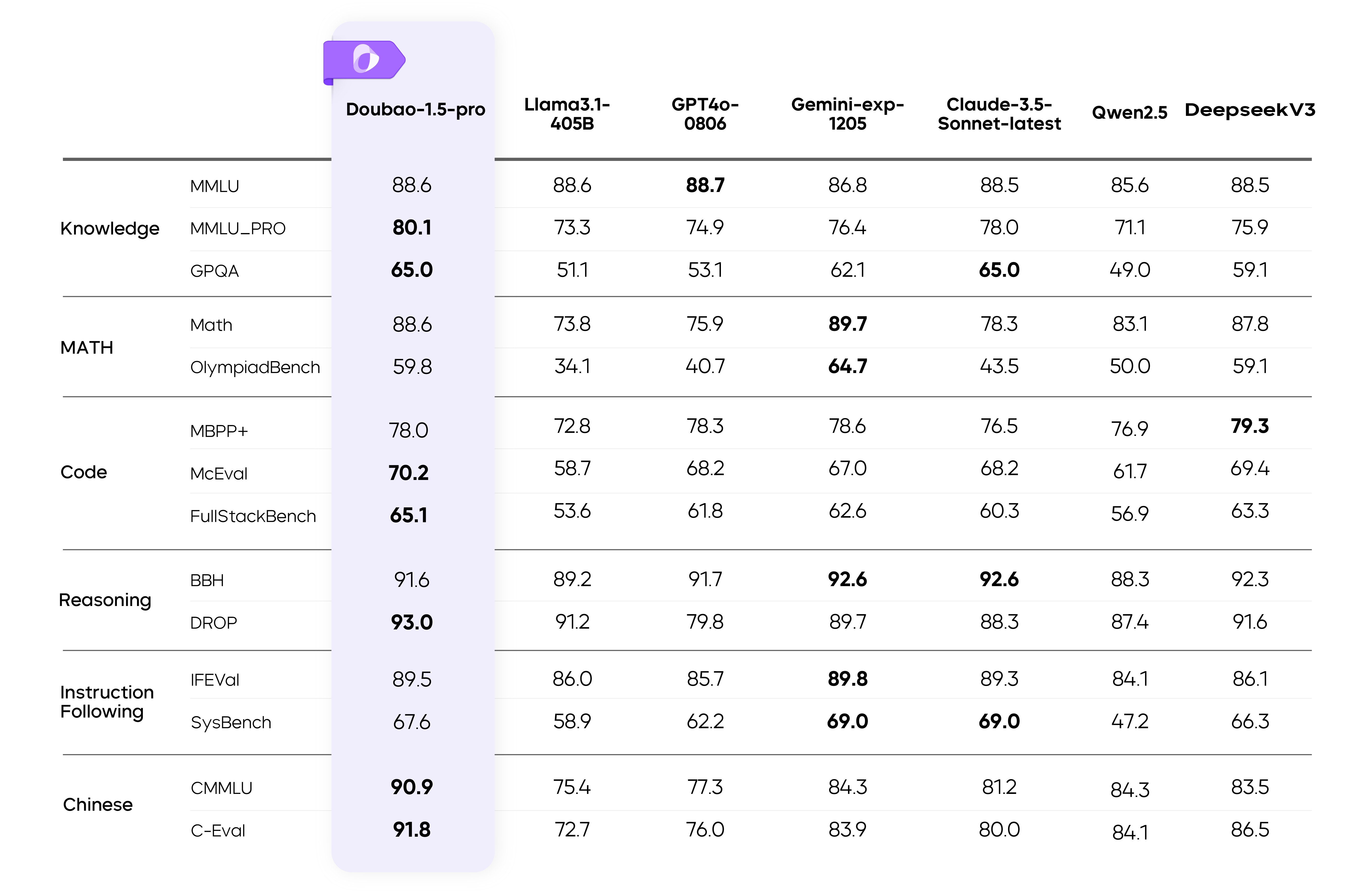
ByteDance introduced their latest multimodal foundation model, Doubao 1.5 Pro. It claims to balance top performance with cost-effective inference, utilizing a flexible server cluster that supports low-end chips to reduce AI infrastructure expenses. In benchmark tests, Doubao 1.5 Pro outperformed several industry leaders, including OpenAI and Anthropic, in various AI capabilities such as language understanding and visual reasoning. (SCMP)
ByteDance’s Doubao chatbot app also added a realtime voice call feature that leverages an advanced AI model to achieve near-human levels of interaction, with significant improvements in voice realism, emotional expression, and conversational abilities in both Chinese and English. (Pandaily)
ByteDance introduced an AI-powered code editor named Trae, aimed at competing with established US products like Cursor and Microsoft’s Visual Studio Code. (SCMP)
The US-China AI competition should shift from a zero-sum race to collaborative efforts for the benefit of humanity, expert said. (MIT Tech Review)
The CEO of MiniMax cautions against the direct application of mobile internet principles to AI development, suggesting that more users do not inherently improve AI models. (LatePost, Translated by Recode China AI)
Trending Research
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
GameFactory: Creating New Games with Generative Interactive Videos
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Nice Tony. Just saw this. Great stuff. Have repacked it (since I had only done notes earlier). Yours has good relevant details.
Great work Tony, I am reference this in new Substack post that will go up tomorrow. Wanted to see what you thought of this: https://www.amd.com/en/developer/resources/technical-articles/amd-instinct-gpus-power-deepseek-v3-revolutionizing-ai-development-with-sglang.html
I am trying to determine what GPU resources DeepSeek has access to. All of the discussion over the past week has focused on H800, A100, and H100, but not on AMD....what is your view of this press release which talks about the "long standing collaboration" between AMD and DeepSeek?