
👀DeepSeek and Z.AI Bet on Visual Compression to Solve Long-Context Problem
Will pixels be better inputs to LLMs than text?


Chinese AI labs are testing an interesting idea to reduce computational costs for processing long context documents: render long text into images and compress it with a vision-language model (VLM). The expected result is fewer tokens without much loss in accuracy.
Over the past week, two new papers have anchored this research direction: DeepSeek-OCR and Glyph.
DeepSeek-OCR: Context as Images, Not Tokens
Last week, DeepSeek researchers published paper DeepSeek-OCR: Contexts Optical Compression. The core idea is to take long text or documents, render them to high-resolution images, compress them to a small number of vision tokens, then decode them back to text.
When LLMs process extremely long text like 1 million tokens, they run into a fundamental problem. The attention mechanism has O(n²) computational complexity. So extending a context window from 50K to 100K tokens will quadruple the computation. That’s why researchers are looking for ways to shorten input sequences.
DeepSeek-OCR has two main components:
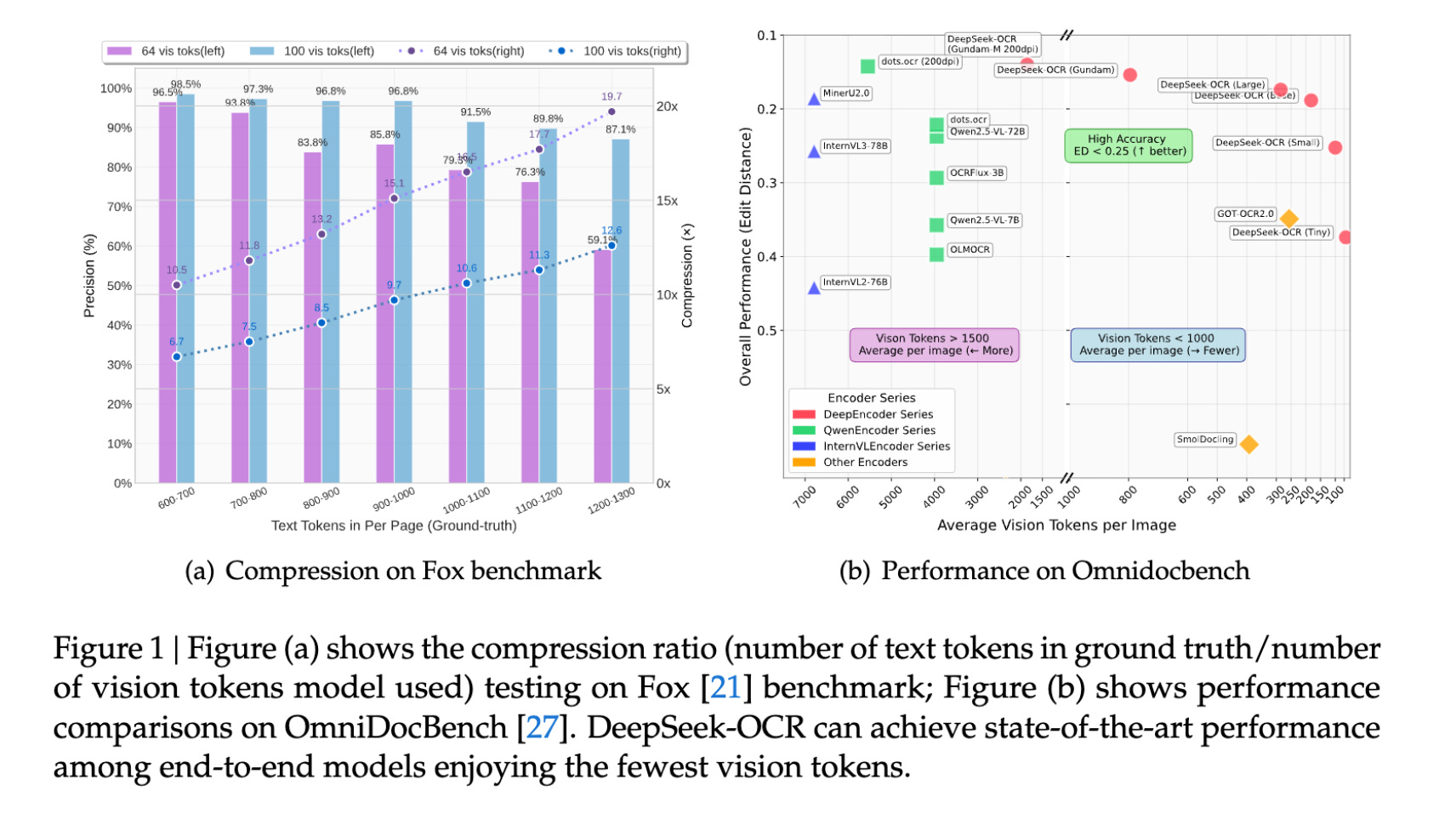
DeepEncoder is a custom encoder that combines SAM-base (window attention) with CLIP-large (dense global attention), plus a 16× token compressor. It offers controllable resolution modes (Tiny/Small/Base/Large/Gundam/Gundam-M).
The LLM is a 3B MoE model with ~570M activated parameters at inference (6 out of 64 routed experts plus 2 shared experts).
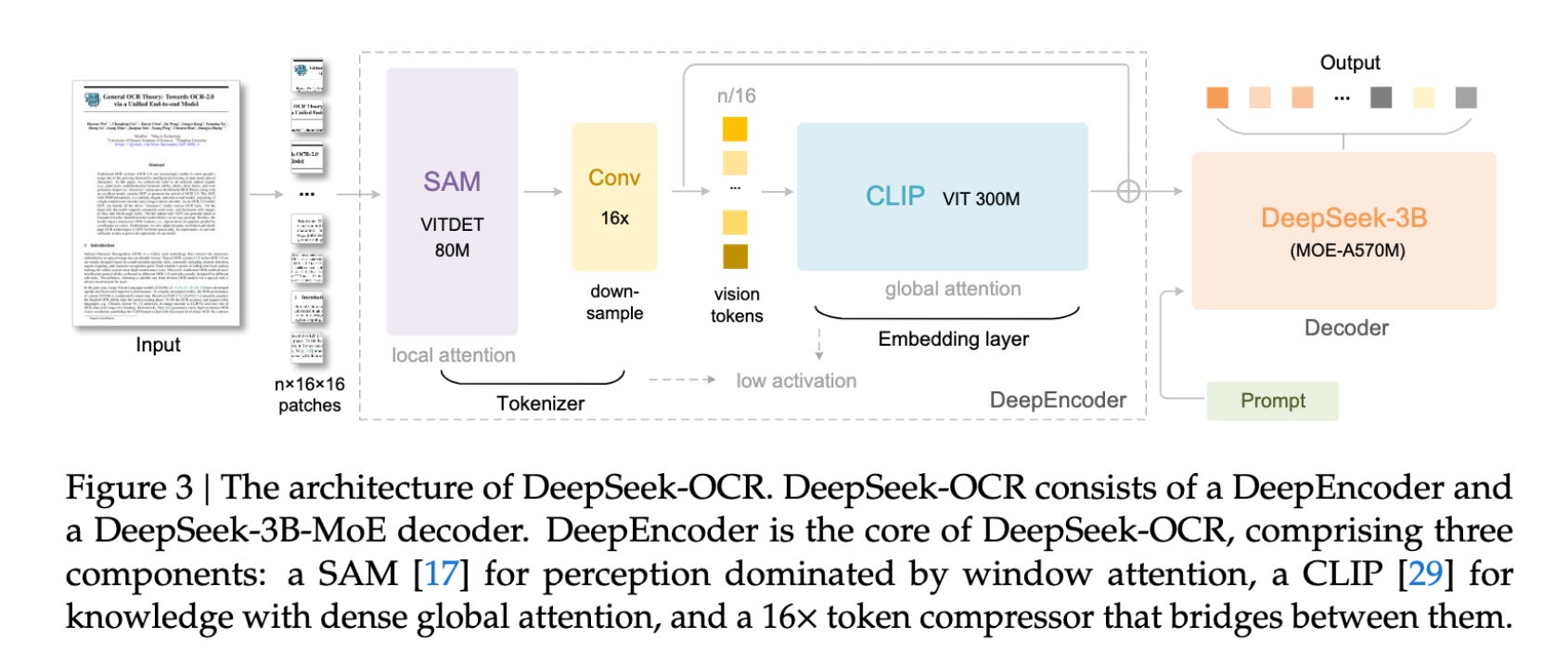
On the FOX benchmark evaluation, the model achieves ~97% decoding precision at ~10 times compression, and ~60–87% precision with more aggressive 15–20 times compressions.
On real document parsing benchmarks, DeepSeek-OCR Gundam-M (1,853 tokens at 200 dpi) scored 0.125 on English. In comparison, general VLMs like Qwen2.5-VL-72B and InternVL3-78B need 3.9k–6.8k tokens to reach scores of 0.214–0.218. DeepSeek-OCR is competitive with state-of-the-art models while using far fewer tokens.
DeepSeek is already using the model to generate over 200K pages per day on a single A100-40G GPU.
Like other DeepSeek models, this one quickly gained traction in the AI community. Former OpenAI and Tesla AI scientist Andrej Karpathy commented on X:
The more interesting part for me (esp as a computer vision at heart who is temporarily masquerading as a natural language person) is whether pixels are better inputs to LLMs than text. Whether text tokens are wasteful and just terrible, at the input.
The DeepSeek brand plus Andrej’s endorsement were enough to make the model the new buzz. Some Chinese media even hailed the model’s breakthrough as “Text is dead, visual shines.”
Of course, not everyone agrees. DeepMind AGI researcher Dileep George, cofounder and former CTO of robotics AI startup Vicarious AI, offered a different take:
I don’t see how converting text to image (’pixels’) makes it any better for language modeling. What am I missing?
Glyph: Visual-Text Compression for Long-Context Reasoning
Interestingly, just one day after DeepSeek-OCR, researchers from Z.ai (Zhipu AI) and Tsinghua University released a similar paper called Glyph (this reminds me of the release of Kimi 1.5 right after DeepSeek-R1 early this year.)
Glyph also tackles the long-context modeling problem head-on. But unlike DeepSeek-OCR, which eventually decodes back to text and evaluates on OCR tasks, Glyph renders long text into images and feeds them directly to a VLM. This compresses the text and enables the model to handle much longer effective context windows.
The training process has three stages:
Continual Pre-Training teaches the VLM to understand and reason over rendered long texts with diverse visual styles.
LLM-Driven Rendering Search automatically discovers the optimal rendering configuration for downstream tasks.
Post-Training includes supervised fine-tuning and reinforcement learning under the discovered configuration to further improve long-context capabilities.
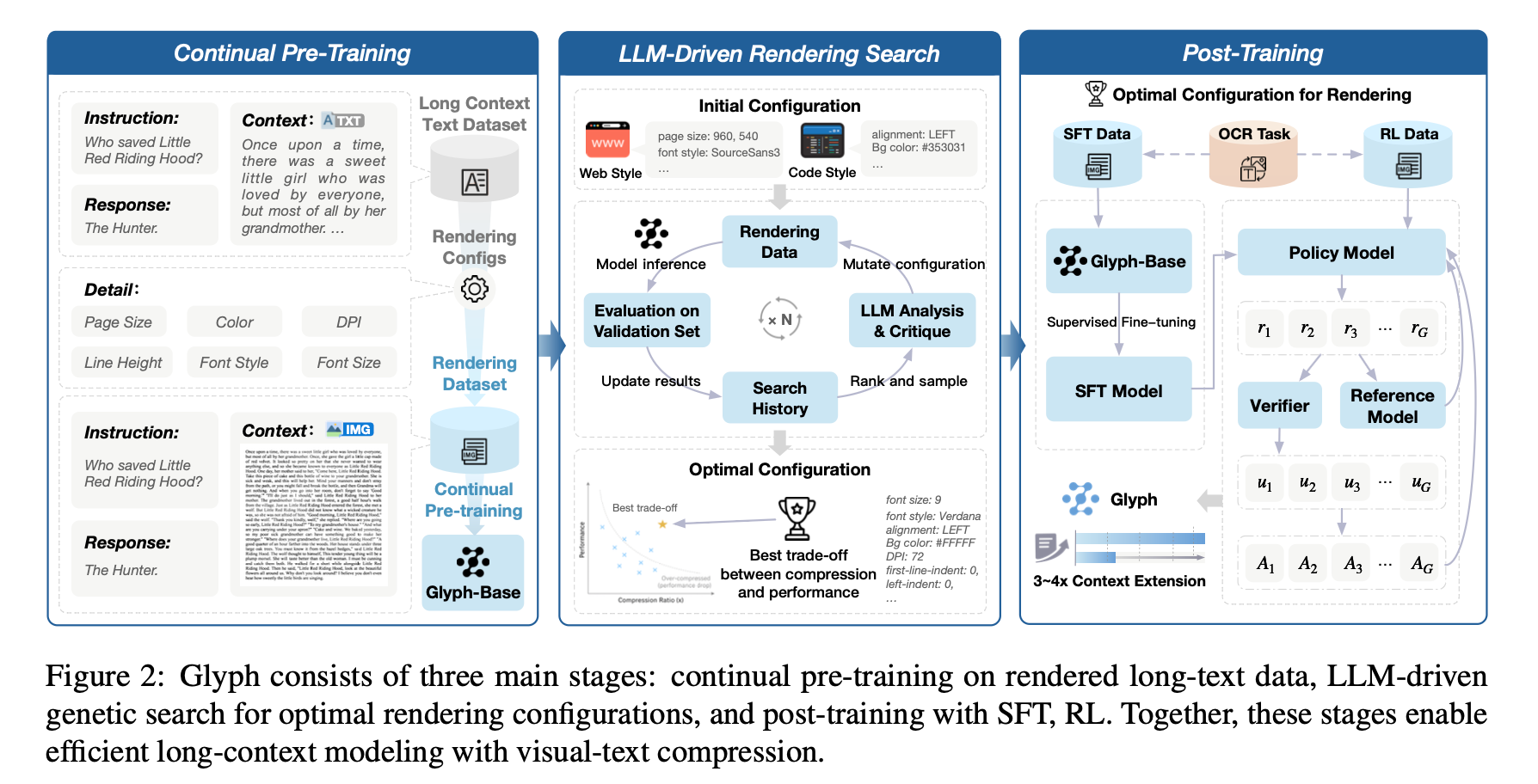
For rendering parameter optimization, researchers use genetic search over configurations including font size, resolution, and layout, which matter for both compression and accuracy. This is fine-grained control that many models ignore.
The paper demonstrates that a VLM processing these rendered images can matchthe performance of text-only models on long-context tasks while using fewer image tokens and achieving faster inference and training.
On benchmarks like LongBench, MRCR, and Ruler, Glyph claims 3–4 times token compression while maintaining accuracy comparable to leading text-only LLMs like Qwen3-8B. Under extreme settings, a 128K-context VLM can stretch to handle ~1M-token-level tasks thanks to compression.
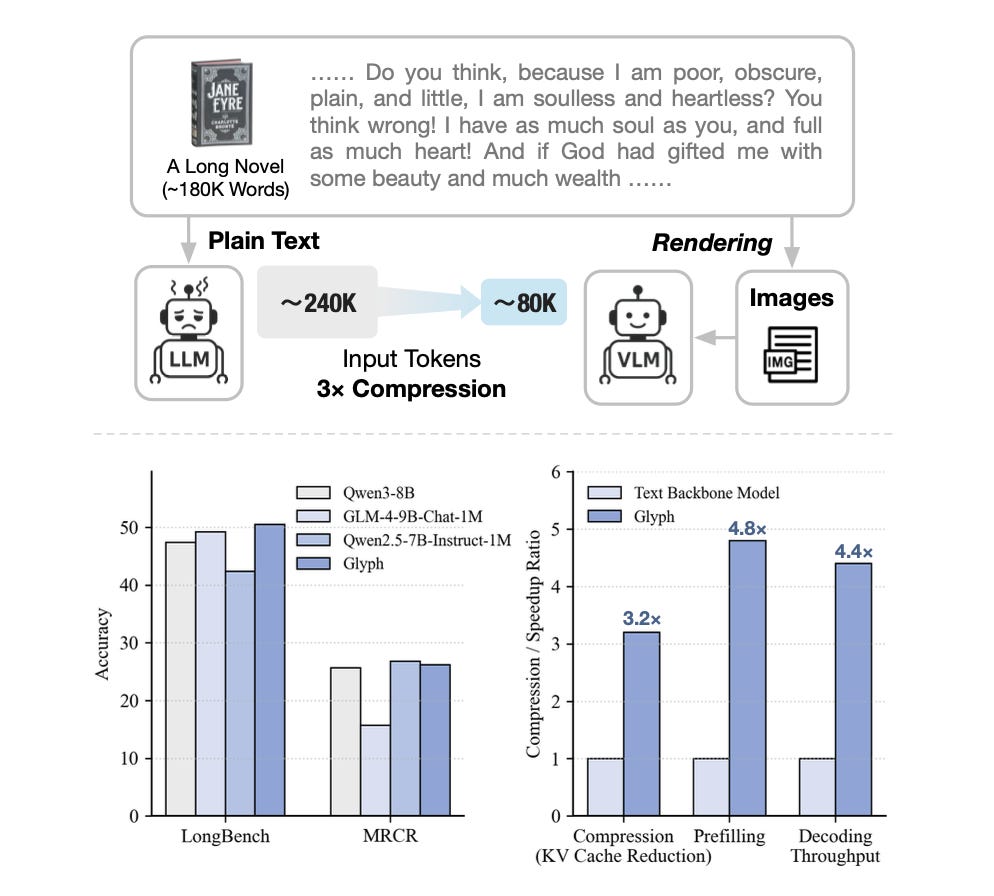
The figures show that on large contexts, Glyph’s inference and training are faster relative to text-only models thanks to reduced token sequence length via compression.
Other Work in This Direction
These aren’t the only two papers exploring this approach:
See the Text: From Tokenization to Visual Reading proposes SeeTok, which renders text as images and uses pretrained multimodal LLMs to interpret them. Across three language tasks, SeeTok matches or surpasses subword tokenizers while requiring 4.43× fewer tokens and reducing FLOPs by 70.5%. Authors are from two Nanjing’s universities and Central South University.
Text or Pixels? It Takes Half shows that visual text representations are a practical and surprisingly effective form of input compression for decoder LLMs. Authors are three Chinese researchers from Allen Institute for AI, University of Chicago, and Stony Brook University.
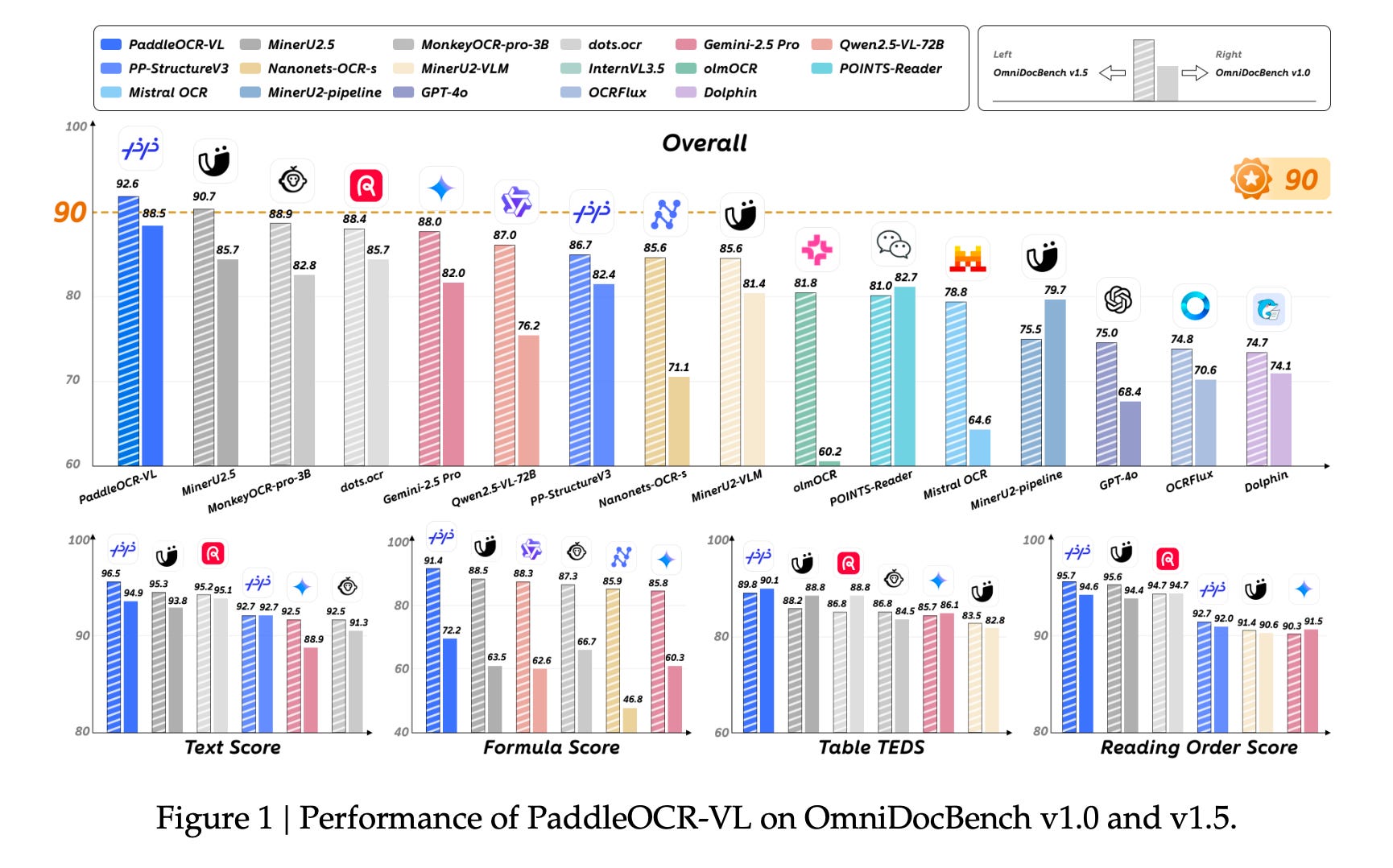
Baidu also unveiled the newest iteration of PaddleOCR, a longstanding model now in its sixth year. Although it does not incorporate text-as-visual compression, this model stands as the SOTA open-source OCR model with only 0.9 billion parameters.
Applications and Limitations
With early experimental success, the potential applications of “text-as-visual” methods are compelling. For example, we can convert chat histories to visuals and keep 10 times more memory for the same budget. Future models with long context windows can process and analyze contracts, statements, research PDFs, tables, and charts at scale with controllable spend-accuracy tradeoffs.
While DeepSeek-OCR proposes great innovations and a potential shift in the current LLM paradigm, there are critical voices questioning whether the reported high compression ratios and high accuracy represent genuine technical breakthroughs.
One argument is DeepSeek-OCR’s success might come from the model’s language priors rather than purely visual understanding. To isolate true visual performance, we’d need controlled tests using random or meaningless character strings.
Another concern is token reduction doesn’t mean real compression if decoding adds extra compute cost. True efficiency requires fewer tokens and lower total compute. OCR accuracy alone isn’t a valid success metric. A better evaluation would test whether the model can answer human-level questions directly from images, not just rebuild text. By this definition, Glyph partly addresses the problem.
From my perspective, the interesting part is the incorporation of encoder-decoder architecture, which dominated in the early Transformer era with models like BERT. But decoder-only Transformers proved easier to scale, easier to train, and better matched downstream use cases like open-ended generation. DeepSeek-OCR brings back a form of encoder-decoder architecture but specifically for context compression. It’s a hybrid approach that keeps the benefits of decoder-only models for generation while using an encoder to handle the inefficiency of processing long input sequences.
Another takeaway is the consistent output of innovative research from Chinese AI labs, from DeepSeek-OCR and Glyph to DeepSeek-R1 and Kimi 1.5. This extends beyond the DeepSeek lab; numerous leading Chinese AI research labs are contributing novel insights into research challenges.
Wow, rendering long text into images to reduce O(n²) complexity really stood out. Such a smart, inovative approach to the long-context problem.