
🤔Inside the OpenAI-DeepSeek Distillation Saga & Alibaba’s Most Powerful AI Model Qwen2.5-Max
I will discuss the controversy surrounding DeepSeek's potential use of OpenAI outputs for training and introduce Alibaba's latest Qwen2.5-Max LLM.


Hi, this is Tony! Happy Chinese New Year! Welcome to this issue of Recode China AI (for the week of January 27, 2025), your go-to newsletter for the latest AI news and research in China.
This week, DeepSeek came under scrutiny for potentially using generated outputs from OpenAI’s platforms to train its models, which violates OpenAI’s terms of service. This practice, known as Knowledge Distillation (KD), refers to transferring advanced capabilities from leading large language models (LLMs) to relatively less powerful ones.
In this post, I will break down what KD is, share my thoughts on whether DeepSeek distilled GPT models, and, if so, explore what this means.
Meanwhile, on January 29 (Beijing Time), the first day of the Chinese New Year, e-commerce giant Alibaba unveiled its latest foundation model, Qwen2.5-Max, which claims surpassing DeepSeek-V3 in multiple benchmarks. Are we entering an age where multiple Chinese AI labs can churn out frontier models?
Inside the OpenAI-DeepSeek Distillation Saga

What’s new: Speculation about KD in DeepSeek’s models first surfaced in December 2024 when users noticed that the DeepSeek chatbot, powered by DeepSeek-V3, sometimes identified itself as ChatGPT. Such discussions continued to spread after DeepSeek-R1 was released in January and became available on the DeepSeek chatbot.

This week, amid the DeepSeek frenzy, Bloomberg reported that Microsoft security researchers discovered individuals suspected to be linked to DeepSeek extracting large amounts of data using OpenAI’s API in the fall. Microsoft notified OpenAI, which subsequently blocked their access.
Later, the Financial Times reported that OpenAI had found evidence suggesting that DeepSeek may have used GPT-generated outputs for model training. OpenAI’s public statement echoed concerns raised by David Sacks, an AI and crypto advisor in the Trump administration, who stated that “it is possible” intellectual property theft had occurred.

What is Knowledge Distillation? KD is a technique where smaller or less advanced AI models learn from more powerful proprietary models like GPT-4 or Gemini. This method is akin to an experienced teacher guiding a student.
According to the paper A Survey on Knowledge Distillation of Large Language Models, KD serves three main functions:
Enhancing model capabilities: Smaller models improve their contextual understanding, task specialization, and alignment with human intent by learning from more advanced models.
Compression of LLMs: KD reduces the model size while maintaining performance to make them more efficient for low-latency deployment.
Self-improvement: Open-source models can iteratively refine themselves using their own distilled knowledge.

Traditional KD techniques rely on logits – the raw, unnormalized output scores (often transformed into a soft probability distribution) from the teacher model – to train the student model. However, this approach requires the teacher model to be white-boxed, meaning its internal architecture, parameters, and outputs must be fully accessible.
Since advanced LLMs like GPT-4 and Gemini are proprietary, black-boxed models that do not provide access to logits, alternative distillation methods have been developed. One common method is supervised fine-tuning (SFT), where the student model is trained directly on the generated outputs of the teacher model.
Distilling knowledge from proprietary models into open-source LLMs is a common practice. For instance, Stanford University’s Alpaca LLM was a 7B LlaMA model trained on a 52K-example dataset, which was generated by prompting GPT-3.5 to produce high-quality, instruction-following responses.

Beyond simple answer generation, Chain-of-Thought (CoT), a step-by-step thought process, can also be distilled. Microsoft’s Orca and Orca 2 leveraged GPT-4 to generate multi-step reasoning chains for complex questions, and then fine-tuned smaller models to mimic this thought process.
Another method is using GPT-4 as a judge to score model responses. The student model is then trained to prefer high-scoring responses to improve their alignment and response quality.
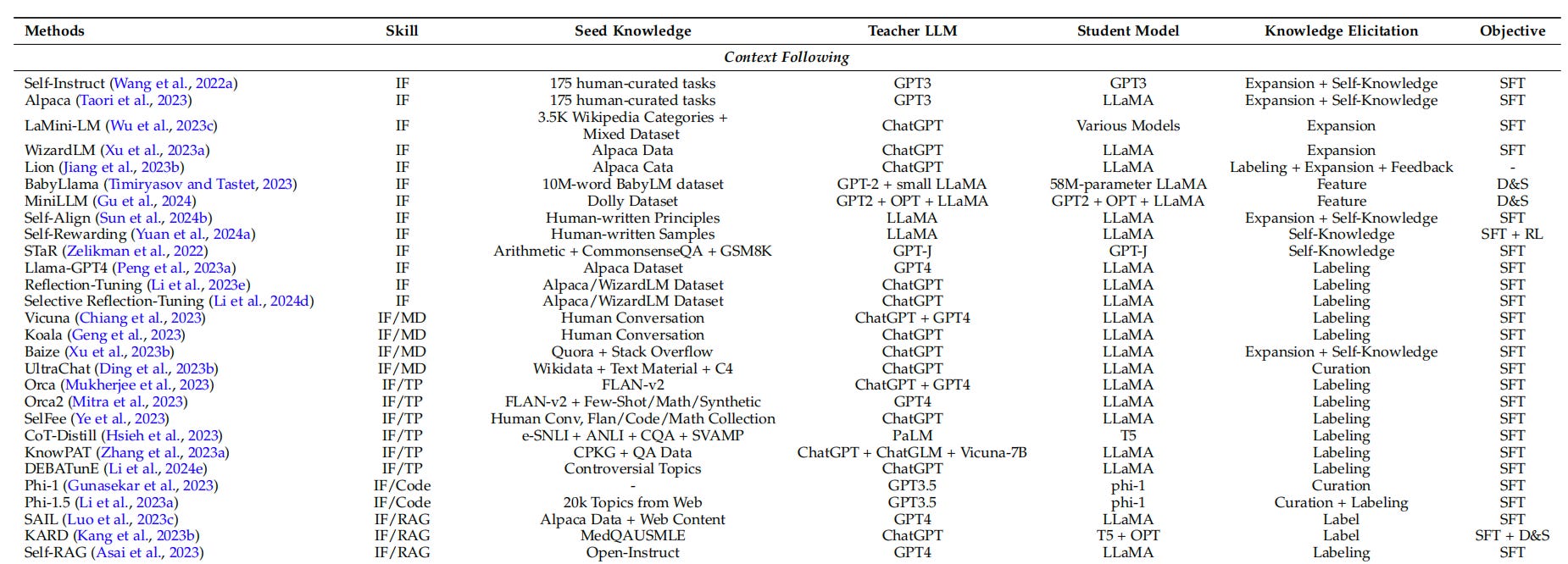
A complementary technique closely intertwined with KD is Data Augmentation (DA), which is a process of generating synthetic training data from a small amount of existing data to improve model performance.
With this understanding of KD, let’s examine what DeepSeek’s papers reveal.
What did DeepSeek papers say? The DeepSeek-R1 paper provided detailed breakdown of its training methodologies. The DeepSeek-R1-Zero was trained exclusively through RL without fine-tuning on datasets, meaning it did not rely on ground-truth data to guide its outputs. In contrast, DeepSeek-R1 was first trained using a cold-start dataset derived from DeepSeek-R1-Zero’s outputs, refined by human annotators, before training through RL.

Another LLM, DeepSeek-V3, was trained on 14.8 trillion tokens. Given the widespread presence of AI-generated content on the internet, it is likely that the dataset contained GPT-generated texts. After pre-training, the model was fine-tuned using 1.5 million examples across multiple domains. For reasoning tasks, training data was collected using an internal DeepSeek-R1 model built on DeepSeek-V2.5, while non-reasoning data was curated using DeepSeek-V2.5 directly.
While DeepSeek did not mention any inclusion of GPT-generated outputs for training, a recent paper, Distillation Quantification for Large Language Models, suggests otherwise. It found that DeepSeek-V3 and Qwen-Max-0919 demonstrated higher distillation levels, aligning closely with GPT-4o, whereas models like Claude-3.5 Sonnet and ByteDance’s Doubao exhibited lower distillation levels. The study looked at how models handle identity-related information, i.e. what model are you, and whether they do so consistently. It also measured how similar the outputs of models were compared to GPT-4o.

If Bloomberg’s report is accurate – given that the data pulling was discovered in the fall of 2024 – individuals linked to DeepSeek may have extracted outputs from OpenAI’s o1-preview API, which was released on September 12, 2024. However, o1 intentionally concealed its CoT process. At best, DeepSeek could have accessed final model outputs, but not the underlying thought process.
My guess is that this extracted data may have been used to develop an early, inside iteration of R1, by fine-tuning DeepSeek’s older base models, such as DeepSeek-V2.5. It later played a role in training DeepSeek-V3, the base model for the official R1 (illustrated in a flowchart below). While DeepSeek successfully improved its model’s reasoning ability through pure RL, it seems unlikely that its initial experiments on reasoning models were conducted without high-quality, reference data.

Another possibility is that a certain amount of GPT-generated outputs were included – intentionally or unintentionally – in DeepSeek-V3’s 14.8T pre-training dataset or its 1.5 million SFT examples.
Please note this remains speculative and lacks definitive evidence.
Why it matters: As mentioned earlier, open-source LLMs distilling from proprietary models is common practice, particularly for startups and university labs with limited budgets for data collection and cleaning. In the past, OpenAI rarely raised complaints about such activities. But DeepSeek is an exception – it presents strong competition to OpenAI in both consumer and enterprise markets.
DeepSeek-V3 and DeepSeek-R1 have demonstrated performance comparable to Anthropic’s Claude-3.5 Sonnet and OpenAI’s o1 models, respectively, but at a fraction of the training and inference costs. As of this writing, DeepSeek remains the most popular free app on the iOS App Store. U.S. enterprises are rushing to integrate DeepSeek into their applications. In response, OpenAI released o3-mini on Friday, a lightweight version of its most powerful reasoning model, o3.

OpenAI has clear legal grounds to warn DeepSeek, as its terms of service explicitly prohibit using OpenAI’s model outputs to train other AI models. Some companies have distanced themselves from the practice to avoid any potential legal consequences. For example, ByteDance emphasized in its Doubao 1.5 release that “in all model training processes, we did not use any data generated by other models, ensuring the independence and reliability of our data sources.”
But the ethical debate surrounding KD is complex for open-source LLMs, which are widely credited with driving AI innovation. OpenAI’s claims against DeepSeek have sparked backlash, with critics questioning why OpenAI itself is allowed to train on unauthorized web data, while simultaneously raising concerns about DeepSeek’s use of generated outputs.

The distillation controversy doesn’t seem to slow down DeepSeek’s strong industry adoption. Microsoft, Dell, Nvidia, and Amazon recently announced support for DeepSeek models, allowing their enterprise customers to deploy and fine-tune DeepSeek R1. Citing a question from Nikkei Asia’s Yifan Yu:
Could anyone please explain why Microsoft would put DeepSeek R1 in its Azure AI Foundry for enterprise customers if they believed the AI model was involved in IP violations or other unethical behavior?
From a tech standpoint, there are indeed risks associated with KD, known as distillation tax. Over-reliance on proprietary model outputs can lead to data homogenization, thus reducing response diversity. If a model depends too heavily on KD, it is unlikely to surpass the teacher model. In DeepSeek’s case, even if some GPT/o1-generated outputs were included in its training data, they are not the sole reason for its strong model performance.
As DeepSeek aims to pursue AGI and become a leading AI lab, stricter adherence to data ethics will be crucial.
Alibaba Drops Qwen2.5-Max on Chinese New Year, Taking Aim at DeepSeek-V3
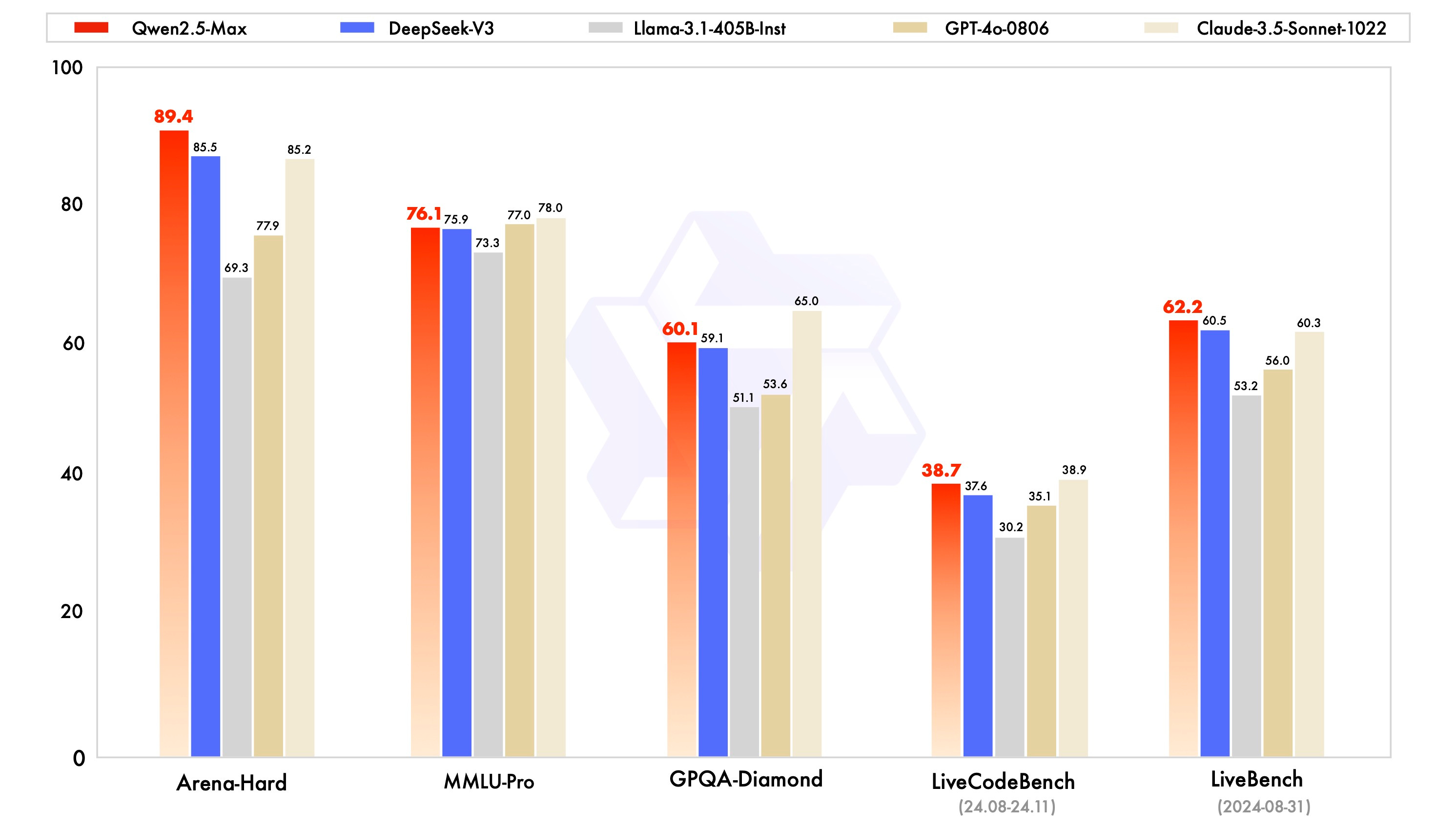
What’s new: On January 29, the first day of Chinese New Year, Alibaba rushed to unveil its latest and most powerful LLM, Qwen2.5-Max, positioning it as a direct competitor to DeepSeek-V3 and other leading LLMs.
The model is available via Alibaba Cloud’s API and Qwen Chat but is not open-sourced.
How it works: Qwen2.5-Max adopts a Mixture-of-Experts (MoE) architecture, which aligns with the broader trend among China’s top LLMs, such as DeepSeek-V3 and MiniMax-o1. Alibaba has two other MoE models, Qwen2.5-Turbo and Qwen2.5-Plus, which perform competitively against GPT-4o-mini and GPT-4o, respectively.
The model was pretrained on 20 trillion tokens of diverse data—surpassing the 18 trillion tokens used for Qwen2.5. However, despite its massive training, Qwen2.5-Max supports only a 32K-token context window.
Post-training involved curated SFT and a multistage RL approach, combining offline Direct Preference Optimization (DPO) and online Gradient-based Reinforcement Preference Optimization (GRPO).
As a result, Qwen2.5-Max achieved a 89.4% accuracy on Arena-Hard, surpassing GPT-4o and Claude 3.5 Sonnet, but lagged behind both models on MMLU-Pro. It also outperformed DeepSeek V3 in benchmarks such as LiveBench, LiveCodeBench, and GPQA-Diamond.
For API pricing, Qwen2.5-Max costs $1.60 per million input tokens and $6.40 per million output tokens — cheaper than GPT-4o and Claude 3.5 Sonnet, but still more expensive than DeepSeek-V3, which charges just $0.27 per million input tokens and $1.10 per million output tokens.
Why it matters: Over the past year, Alibaba’s Qwen series and DeepSeek have emerged as the two leading LLM brands in China, driven by rapid iteration and an aggressive open-source strategy. The Qwen series has been adopted among Chinese developers due to its various model sizes catering to diverse use cases.
However, DeepSeek’s meteoric rise has clearly put pressure on Alibaba, forcing it to accelerate its own releases. Two days before the unveil of Qwen2.5-Max, Alibaba open-sourced its latest multimodal model, Qwen2.5-VL, which can understand videos and control PCs and smartphones. The release includes both base and instruction-tuned models in three sizes: 3B, 7B, and 72B. Qwen2.5-VL-72B outperforms OpenAI’s GPT-4o and Google's Gemini 2.0 Flash in document analysis, video understanding, and agent tasks.

Let’s be honest: dropping LLMs on the first day of Chinese New Year is a crime against naps and dumplings. Still, kudos to the Qwen team — they pulled off an impressive launch under pressure.
Looking ahead, as progress on next-gen frontier models like GPT-5 is slowing further than anticipated, it’s increasingly likely that Chinese AI labs will continue to narrow the performance gap with U.S. leaders — while maintaining a significantly lower price point.