
🐳China's ChatGPT Moment: How DeepSeek Rewrites the Rules in 30 Days
A 20-month-old AI startup's breakthrough model captures global attention, amasses 100 million downloads, and forces China's tech giants to rethink their AI strategies.


Hi, this is Tony! Welcome to this issue of Recode China AI (for the week of February 24, 2025), your go-to newsletter for the latest AI news and research in China.
In this post, I share my latest thoughts and analysis on DeepSeek. I try to break down what’s driving its success and explore how it’s influencing not just China’s AI development, but the global tech landscape too.
A Month of Unstoppable Momentum
It has been more than a month since DeepSeek, a 20-month-old Chinese AI startup, open-sourced DeepSeek-R1—a reasoning model that rivals OpenAI’s o1 in performance while offering at a fraction of the cost. Yet, the ripple effects of this release show no signs of slowing down.
Powered by R1, the DeepSeek chatbot quickly became a sensation. The app surpassed 100 million total downloads within 30 days, according to Beijing-based data analytics firm QuestMobile, and briefly overtook ChatGPT as the most downloaded free app on the U.S. iOS App Store in late January. Its meteoric rise also triggered a staggering 18% drop in Nvidia’s stock price on January 27, 2025, due to concerns that demand for Nvidia’s high-performance GPUs might decrease as DeepSeek’s model required less powerful hardware.

DeepSeek’s influence in China intensified after the seven-day Chinese New Year holiday, as businesses resumed operations and the demand for AI spiked. Over 200 Chinese companies—from smartphone makers to telecom operators—have announced support or integration with R1.
Chinese cloud computing platforms have been among the biggest beneficiaries. Infrastructure startup SiliconFlow, in collaboration with Huawei and its Ascend 910B AI chips, became the first platform to host R1 and DeepSeek-V3, DeepSeek’s newest foundation model, via cloud APIs. Within 10 days, SiliconFlow’s website traffic surged 30-fold, briefly surpassing Alibaba Cloud. DeepSeek’s API service crashed on launch day under overwhelming demand. Other cloud providers, including ByteDance’s Volcano Engine, shared similar experiences after hosting DeepSeek’s models.
Chinese consumer apps are also racing to jump on the R1 bandwagon. In early February, Tencent began beta testing an AI-powered search feature based on R1 on WeChat, the Chinese super app with 1.3 billion users. Tencent also integrated R1 into its standalone chatbot Yuanbao and 10 other Tencent products. As a result, Yuanbao’s web traffic skyrocketed by 250% in a single day. Meanwhile, Baidu has also integrated the model into its search engine, alongside its proprietary LLM, ERNIE.

DeepSeek’s unprecedented popularity quickly drew the attention of China’s top leadership. Within just a month, DeepSeek CEO Liang Wenfeng was invited to meetings hosted by Chinese President Xi Jinping and Premier Li Qiang. DeepSeek’s models have also received warm welcomes from local governments in Beijing, Shanghai, Shenzhen, and dozens of other cities, which rushed to apply DeepSeek’s models in their daily operations, such as processing documents and scrutinizing investments.

Why has DeepSeek succeeded and gained so much attention? What does this mean for other Chinese AI players? More importantly, what opportunities and challenges lie ahead?
Pursuing AGI Through Exploration and Research
In its first research paper, published in January 2024, DeepSeek researchers challenged Google DeepMind’s widely recognized Chinchilla Scaling Laws—rules that balance model parameters with training data for optimal performance. Instead, DeepSeek researchers figured out the scaling laws for hyperparameters—a setting that controls how the model learns from data—and proposed a new metric called non-embedding FLOPs per token to track the compute an AI model uses for each token it learns. These methods aim to more accurately predict and optimize the model’s efficiency during scaling experiments.
It’s unusual for a startup like DeepSeek to conduct such fundamental research, which is typically reserved for academic institutions or established industry labs. “DeepSeek acts like an academic lab,” said He Junxian, a computer scientist from the Hong Kong University of Science and Technology, in a recent podcast.
In subsequent papers, DeepSeek continued to disrupt conventional AI training methods. The team introduced DeepSeekMoE, a Mixture-of-Experts (MoE) architecture, and Multi-Level Attention (MLA)—two key components that significantly reduce training costs while maintaining high performance. DeepSeekMoE selectively activates only a fraction of parameters for each task, enabling the model to scale from 67 billion parameters in V1 to 234 billion in V2 while reducing both training and inference costs. Similarly, the MLA method improves model efficiency by compressing Key/Value vectors into smaller “latent” vectors, minimizing KV cache size to reduce compute demand.
R1 marked another milestone by training a reasoning model purely through reinforcement learning (DeepSeek-R1-Zero, specifically). Without supervised fine-tuning, R1-Zero can still learn to reflect and even explore alternative problem-solving paths. OpenAI Chief Research Officer Mark Chen acknowledged that “DeepSeek managed to independently find some of the core ideas OpenAI had used to build its o1 reasoning model.”
“Among Chinese AI labs, DeepSeek is one of the very few companies genuinely innovating,” an industry researcher told me in mid-2024.
Innovation is, without a doubt, central to DeepSeek’s rising prominence. In China’s fiercely competitive AI market, many tech giants and startups follow established paths rather than fundamental research to minimize risk. DeepSeek, in contrast, remains dedicated to its long-term vision of achieving Artificial General Intelligence (AGI). CEO Liang emphasized in a previous interview: “Our goal is very clear—we don’t chase quick wins in specialized applications but focus on exploration and research.”
Liang’s leadership plays a crucial role in steering DeepSeek toward innovative research. He insists on open-sourcing their findings and reportedly even labels training data himself. “If we were only replicating existing models, the costs would be minimal,” Liang said. “True research demands rigorous experimentation, extensive compute, and exceptional talent, all of which are more costly.”
Not all startups can afford the high costs of innovation, but DeepSeek is well-positioned to sustain these investments. The startup is backed by High-Flyer, one of China’s top quantitative investment funds, which managed up to 100 billion yuan (approximately $15 billion) at its peak. Industry insiders revealed that DeepSeek’s first phase of R&D was fully funded by High-Flyer, with an initial investment of 3 billion yuan (approximately $413 million).
As a quantitative fund-backed startup, DeepSeek possesses deep expertise in GPU utilization. Quantitative funds process vast amounts of financial data in real-time, requiring high-performance computing, parallel processing, and machine learning models. High-Flyer has built a cluster of over 10,000 Nvidia A100 GPUs, acquired before U.S. export controls took effect in late 2022. The DeepSeek-V3 research paper further highlights how they meticulously optimize computing resources by refining every level—from GPUs to interconnections and data quantization.
DeepSeek’s success is also attributed to its flat organizational structure, inherited from High-Flyer, where innovation thrives without rigid KPIs or hierarchies. This structure contrasts with the more traditional corporate cultures of many Chinese companies, which often emphasize clear chains of command and performance metrics. Chinese media reported that the company maintains a lean team of around 150, primarily composed of recent graduates and young researchers. “Innovation often arises spontaneously, not through deliberate arrangement, nor can it be taught,” Liang said.
On a separate note, innovation alone does not fully explain why DeepSeek has gained so much attention. Several factors contribute to its growing attention:
A research direction focused on developing effective models at minimal cost appears to offer greater value than many other research priorities today, as it accelerates the adoption of LLMs.
DeepSeek’s open-source nature and detailed technical papers have granted it more exposure to the global AI community compared to its Chinese peers. Developers and AI enthusiasts worldwide have studied its research papers, experimented with its models, and shared positive feedback on social media. Additionally, DeepSeek’s chatbot app is freely accessible to all users, which allows a broader audience to test its capabilities firsthand.
Due to limited global awareness of China’s advancements in AI, the sudden rise of a previously lesser-known Chinese AI lab has captured widespread attention and curiosity.
DeepSeek's Influence on Chinese AI Players
As China’s AI sector adapts to DeepSeek’s disruptive influence, one thing is clear: the shift toward deeper innovation and open collaboration has begun.
The success of DeepSeek has forced other Chinese AI players, represented by ByteDance and Alibaba, to rethink their AI strategies and ramp up investments in fundamental innovation.
ByteDance CEO Liang Rubo recently said in an all-hands meeting that the company’s goal for 2025 is to push the limits of intelligence. Instead of focusing on specific products—such as Doubao, its popular chatbot—the company aims to foster broader experimentation and ensure key technological advancements are not overlooked. Additional objectives include exploring new interaction, such as AI headphones, and strengthening scaling effects.

Before DeepSeek’s rise, ByteDance’s chatbot Doubao was the most popular AI app in China, far ahead of competitors in terms of daily users. ByteDance’s AI technology, from its Seed LLM series to its image generation models, was considered top-tier in China. However, the parent company of TikTok faced unexpected pressure when DeepSeek’s chatbot app soared to the top of app stores, garnering over 30 million daily users without any marketing or promotions—quickly dethroning Doubao. As of today, ByteDance has yet to develop a reasoning model.

Reflecting on this shift, Liang acknowledged that ByteDance had been slow to react when OpenAI introduced its reasoning model in September 2024. “Looking back, had we acted sooner, we could have led the way,” Liang said.
To accelerate progress, ByteDance recently brought in Dr. Wu Yonghui, former Vice President of Research at Google DeepMind, to lead fundamental AI research. Wu, one of the highest-ranking Chinese AI researchers at Google, played a key role in developing the Gemini model series.
In January 2025, ByteDance reportedly launched a long-term AGI research initiative, codenamed Seed Edge. Its key research areas span next-generation reasoning, world models, new architectures beyond Transformer, new hardware, and scaling.
Alibaba has also moved swiftly to address DeepSeek’s challenge. As one of China’s leading contributors to open-source AI, Alibaba's Qwen series remains the most downloaded LLM on HuggingFace. Just a week after R1’s release, Alibaba introduced Qwen2.5-Max, a powerful LLM that outperforms DeepSeek-V3 across multiple benchmarks.
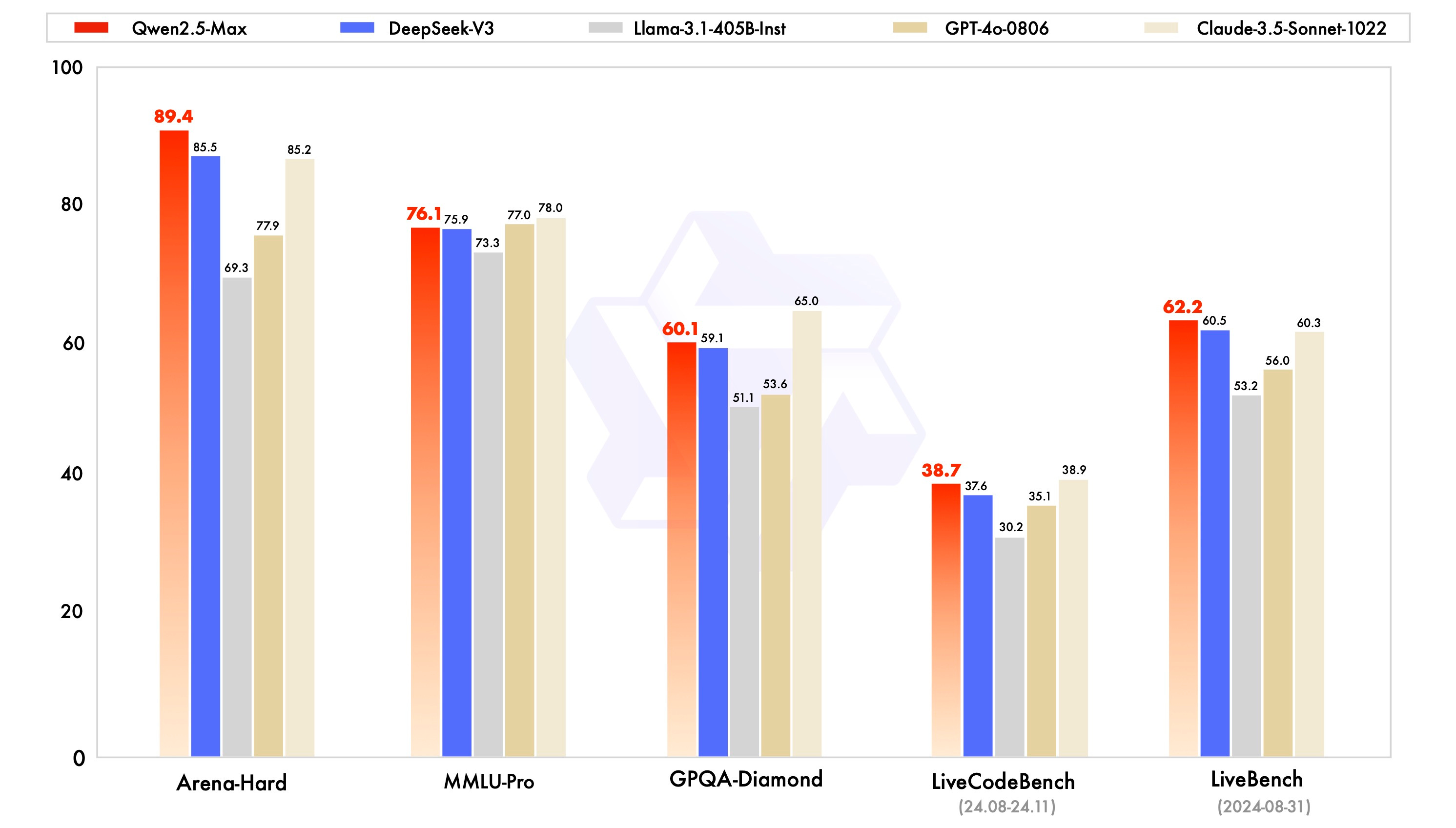
Building on Qwen2.5-Max, Alibaba also previewed its reasoning model, QwQ-Max, designed to compete with OpenAI’s o1 and R1. Both QwQ-Max and a base version of Qwen2.5-Max will be open-sourced, alongside a dedicated chatbot app under the Qwen brand.
In late February, Alibaba announced a historic $53 billion investment in cloud and AI infrastructure over the next three years—the largest private AI computing initiative in China’s history. Beyond infrastructure, CEO Eddie Wu pledged to significantly increase R&D spending on foundation models to sustain Alibaba’s technological leadership and drive AI-native applications.

Another significant shifts in China’s AI industry is a growing commitment to open-source strategies. Before DeepSeek, open-source was not a popular choice for Chinese AI developers. Both Chinese tech giants and startups have heavily invested in AI and preferred to keep their proprietary models closed to maintain a competitive edge.
However, even Baidu, whose CEO Robin Li had long dismissed open-source LLMs as inferior to proprietary models, recently reversed course. His company announced that it will open-source its ERNIE 4.5 model series starting June 30, 2025.
Explaining this strategic pivot, Li acknowledged, “One thing we learned from DeepSeek is that open-sourcing the best models can drive adoption. When a model is open-source, people naturally want to experiment with it, which leads to wider usage and faster improvements.”
Other previously closed-source AI companies, such as Alibaba-backed Moonshot AI and Tencent-backed MiniMax, are also embracing open-source strategies to gain traction within the AI community. In February, Moonshot AI introduced and open-sourced Muon and Mooncake, aimed at supporting the research community by providing efficient tools for LLM training. Earlier this year, MiniMax open-sourced its MiniMax-01 series of models, which feature a novel Lightning Attention mechanism capable of processing up to 4 million tokens during inference.

While open-source models are generally free, this does not preclude commercial returns. Alibaba CEO Wu said in the company’s latest earning call that, “Our Qwen model is open-source, but that doesn’t mean it’s free. We do charge for API access on our Bailian platform. While these revenues are modest today, as models grow more powerful and capable, monetization opportunities will expand.”
Wang Tiezhen, a Hugging Face engineer, pointed out that open-source models serve as tools whereas closed-source models function as products. “Unlike closed-source models that offer plug-and-play API access, open-source models require an in-house engineering team to handle deployment, optimization, and scaling,” he explained.
Notably, while many open-source AI projects primarily share trained model weights (i.e., parameters), a truly open-source LLM would also include the underlying source code and, ideally, the training data. However, even DeepSeek has not disclosed its training data, which is a key factor behind its impressive performance and ability to generate human-like responses.
“I hope the open-source community will contribute more data so that we can make greater progress together under new AI paradigms,” said Harry Shum, a well-known computer scientist and former Microsoft EVP of AI & Research.
Opportunities and Challenges Ahead
More than two years after ChatGPT’s release, China has finally embraced its own “ChatGPT moment.” Tens of millions of Chinese users who had never used ChatGPT now have access to an AI chatbot with comparable performance—and it’s free. Some have praised DeepSeek for its superior writing quality and out-of-box conversational style. Enterprise users, too, are gaining higher returns on investment by integrating DeepSeek into their workflows.
However, DeepSeek is struggling to keep up with the influx of users due to compute shortage. Many who attempt multi-round conversations encounter the dreaded “server busy” message. This has created opportunities for competing platforms that provide access to R1, and even chatbots without R1 access have benefited from the surge in AI adoption. According to SimilarWeb data, post-Chinese New Year traffic for Doubao’s web version spiked 27% compared to the pre-holiday peak, while Moonshot AI’s Kimi saw an even larger 54% increase.

The rapid advancement of open-source LLMs is giving everyone access to high-performing AI. It liberates AI application companies from the costly burden of developing proprietary LLMs, allowing them to focus on building AI-powered products. This contrasts a consensus over the past two years that Chinese AI entrepreneurs believed success required both proprietary models and AI applications. The idea was that homegrown models would provide a competitive edge, while feedback from applications would, in turn, improve the models. DeepSeek’s emergence has upended this ideology. Suddenly, having a proprietary model seems less important.
In the U.S., this separation between models and applications has already taken shape. Only a handful of companies—OpenAI, Google, Anthropic, Meta, and xAI—are still building foundational models. Meanwhile, application-focused startups like Perplexity and Cursor remain model-agnostic. They prioritize product innovation over model development. As LLMs become cheaper and trial costs drop, we can expect a new wave of AI app experimentation in 2025 and beyond.
The R1 paper also demonstrated that smaller LLMs, using techniques like data distillation, can perform surprisingly well on complex reasoning tasks. Some researchers have already extracted tens of thousands of distilled datasets from R1 to train smaller models—a positive development for compute-constrained devices like smartphones and, potentially, robots. Improved reasoning capabilities will also accelerate the rise of AI agents capable of autonomously executing tasks on behalf of users.
The key question for DeepSeek is: what’s next? While significantly reducing costs without compromising performance is an impressive achievement, DeepSeek has yet to push the boundaries of intelligence in a meaningful way. The Chinese AI community now has high hopes that DeepSeek and other labs could take their innovations further. This week, DeepSeek doubled down on open-source technologies by releasing five new code repositories. Reuters reports that DeepSeek is rushing to release R2, its next-generation reasoning model.
Looking ahead, Chinese AI labs may explore new techniques—and possibly even architectures beyond Transformer—to achieve breakthroughs. But innovation won’t come easy. U.S. chip restrictions remain the biggest challenge. DeepSeek managed to acquire around 3,000 Nvidia H800 GPUs—a restricted version of the flagship H100—to train DeepSeek-V3. While the H800’s limited interconnect bandwidth slows data communication between chips, its raw compute power matches that of the H100.
After additional export controls in October 2023, the H800 is no longer available in China. The most advanced Nvidia GPU now accessible to Chinese companies is the H20, which delivers just one-sixth of the H100’s peak compute performance. Designed primarily for LLM inference rather than training, the H20 has still seen a surge in orders as DeepSeek’s models gain adoption, Reuters reported.
Despite China’s rapid progress in developing domestic AI chips—such as Huawei’s Ascend 910B and 910C—Nvidia GPUs remain the gold option for LLM training. With the U.S. considering even stricter semiconductor restrictions under the second Trump administration and pressuring allies to tighten their own curbs, China’s pace of AI innovation could be affected in the short term.
Another challenge is AI lacks a sustainable business model, and the timeline to AGI remains uncertain. Can DeepSeek afford to keep innovating without financial returns? The Information reports that DeepSeek is considering raising outside funding for the first time. In comparison, OpenAI has raised $6.6 billion in its latest funding round at $157 billion. Even Ilya Sutskever’s new company, Safe Superintelligence (SSI), is raising over $1 billion in funding at a valuation exceeding $30 billion.
DeepSeek has proven that fundamental research and open-source can drive success, but sustaining its momentum will require strategic investments, regulatory adaptability, and continuous innovation. Besides, other competitors are flexing their AI muscles in response by churning out more powerful LLMs, such as OpenAI’s o3, Anthropic’s Claude-3.7-Sonnet, and xAI’s Grok 3. The global AI race is far from over.
One thing is certain—DeepSeek has already changed the game, and the world is watching what comes next.