
💪🏻AI Makes Alibaba Great Again
This feature examines how Alibaba, once known for e-commerce, has transformed into an AI powerhouse.


“Make Alibaba Great Again” has been circulating inside the company for more than a year—and the numbers suggest it’s happening.
The Chinese e-commerce and cloud computing giant just turned in its best year since 2022. The stock is up over 90% year-to-date (as of September 19, 2025), a rally built on a fast-maturing AI push. In the June quarter of 2025, the company’s AI-related product revenue surged triple digits, while cloud sales beat Wall Street expectations with a 26% year-on-year increase.
At the 2025 Apsara conference in September, CEO Eddie Wu ambitiously said Alibaba is executing a three-year ¥380 billion ($53 billion) investment in AI and cloud infrastructure, and positioned Qwen, the company’s large language model (LLM) family, as the “Android of the AI era.”
Wu’s remarks coincided with Alibaba’s rising recognition as a leading force in global open-source AI. By the company’s statistics, Qwen has become the world’s largest open-source model family, with more than 400 million cumulative downloads and 140,000 derivatives. Developers and enterprises globally have been utilizing Qwen to create AI products, such as Japanese customer service chatbots and integrated assistants for cars.
At the conference, Alibaba Cloud CTO Zhou Jingren released a sweeping lineup of new AI models. Its latest LLM Qwen3-Max, boasting one trillion parameters, outpaced rivals including Claude Opus 4 and DeepSeek V3.1 in agent benchmarks. He also unveiled six additional models spanning everything from the Wan 2.5 video generator to the multimodal Qwen3-VL, a signal that Alibaba is gunning for dominance across every corner of the AI landscape.
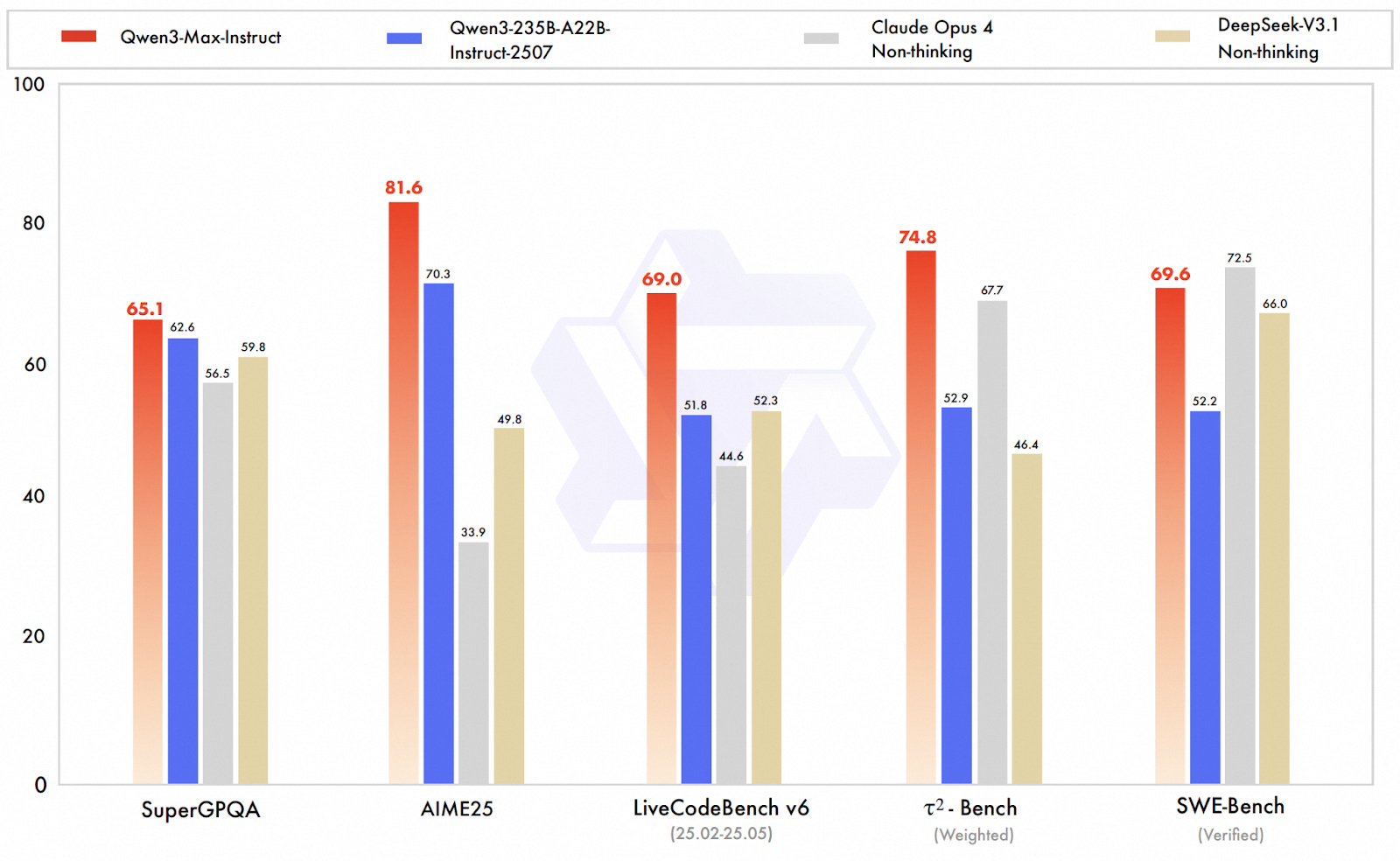
The aggressive rollout isn’t new. In recent weeks alone, Alibaba unveiled Qwen3-Next, which offers comparable performance at a significantly reduced training cost, and an open-sourced agentic model, Tongyi DeepResearch, for deep information seeking. On the Artificial Analysis Intelligence Index, a well-respected benchmark for language model evaluation, two Alibaba models ranked among the top 10 contenders.
The pace is cutthroat: According to unofficial statistics, Alibaba has released 357 models in less than two years.

“We’re the only company [in China] that both runs a leading cloud business and is competitive in AI,” Alibaba Chairman Joe Tsai said in 2024 at a J.P. Morgan’s event. “The combination of AI and cloud is important.”
Besides models and cloud, Alibaba is embedding AI throughout its sprawling empire, from the fundamental chips to consumer-facing applications. The company is leveraging its homegrown AI chips to train LLMs. Its enterprise solutions like DingTalk and consumer-facing applications such as Quark, powered by AI, are formidable contenders in their respective arenas. Alibaba’s Qwen models are also being tailored for the latest consumer electronics, including RayNeo’s smart glasses.

Alibaba’s progress in AI has also been welcomed by the Chinese government. In February, founder Jack Ma’s surprise reappearance at a high-profile meeting with Chinese President Xi Jinping and other business leaders is widely read as a signal that the private tech crackdown is over. The government is re-engaging entrepreneurs and aligning them with priorities such as AI. A recent Bloomberg feature noted that Ma, after retreating from public view during the 2020 antitrust probe, is now more directly involved than he has been in the past five years.
This feature examines how Alibaba, once known for e-commerce, has transformed into an AI powerhouse—a shift that even Amazon hasn’t managed to achieve. Given the company’s scale, it’s impossible to cover all of its AI businesses and applications in a single story. Instead, the focus here is on Qwen.
1. DAMO Academy and M6
Before we dive into Qwen, we need to understand its origin and background: Does Qwen come out of nowhere? Where is the origin of Qwen?
Back in 2014, Alibaba was already China’s e-commerce titan. Flush with cash and riding a historic U.S. IPO, the company created its research and development unit called Institute of Data Science and Technologies (iDST). Located in Silicon Valley, Seattle, Beijing, and Hangzhou, the institute was charged with pushing the frontier of technologies such as speech recognition, computer vision, and machine learning.
Three years later, Alibaba was at its peak. With a market cap of $470 billion—surpassing Amazon at the time—Alibaba commanded 25,000 engineers and more than 500 million users. Founder Jack Ma wanted more than an e-commerce business. He wanted Alibaba to be a great company. Just as Microsoft, Bell Labs, and IBM built research labs that shaped entire industries, Alibaba needed its own.
So in 2017, Ma announced the creation of DAMO Academy—short for Discovery, Adventure, Momentum and Outlook. Backed by a promised $15 billion investment over the subsequent three years, DAMO was designed as a world-class research hub tackling problems from autonomous driving to quantum computing. Alibaba folded iDST and other core labs into DAMO, creating a sprawling structure: five labs in machine intelligence, three in computing and databases, one in robotics, three in fintech, plus frontier “X-labs” in quantum and exploratory AI.

From the start, natural language processing (NLP) and large language models (LLMs) were not DAMO’s central focus, as language technologies were not considered critical to Alibaba’s e-commerce core. Yet in parallel, a revolution was brewing on the other side of the Pacific: in 2017 Google researchers invented the Transformer architecture, which quietly began reshaping NLP.
In October 2018, Google released BERT, a 110-million-parameter Transformer-based model that excelled at language understanding, making it remarkably effective at tasks such as interpreting the intent behind search queries.
Two years later, in May 2020, OpenAI released GPT-3, a landmark LLM that not only demonstrated astonishing language generation but also outperformed BERT in understanding. The scale shocked the AI community: 175 billion parameters—then thought impossible.
The shockwave, despite COVID-19’s disruption of international academic exchange, reached China. Inspired and alarmed by U.S. breakthroughs, Chinese AI labs rushed to train their own LLMs. The state-backed Beijing Academy of Artificial Intelligence (BAAI) launched its WuDao project. Baidu rolled out ERNIE 3.0 within a year. Huawei started its Pangu LLM.
DAMO, for its part, launched two projects: M6 and AliceMind. M6 was Alibaba’s bid to catch up with GPT-3, led by Zhou Jingren (head of DAMO’s intelligent computing lab), scientist Yang Hongxia, and a team of young researchers such as Zhou Chang and Lin Junyang (note: Zhou and Lin would later play key roles in Qwen).
By 2021, DAMO Academy had scaled M6 to 10 trillion parameters—at the time, the largest AI model in the world. More impressive was the efficiency: Alibaba trained M6 in just 10 days on 512 GPUs, claiming it used only 1% of the energy GPT-3 would have consumed at a comparable size. M6 was multimodal, trained on 200GB of text and 2TB of images. That made it a natural fit for e-commerce, where it could churn out product descriptions, design ad campaigns, and sketch fashion concepts. Still, M6 was not dedicated to open-domain language generation or reasoning, so its writing and Q&A skills lagged far behind GPT-3.
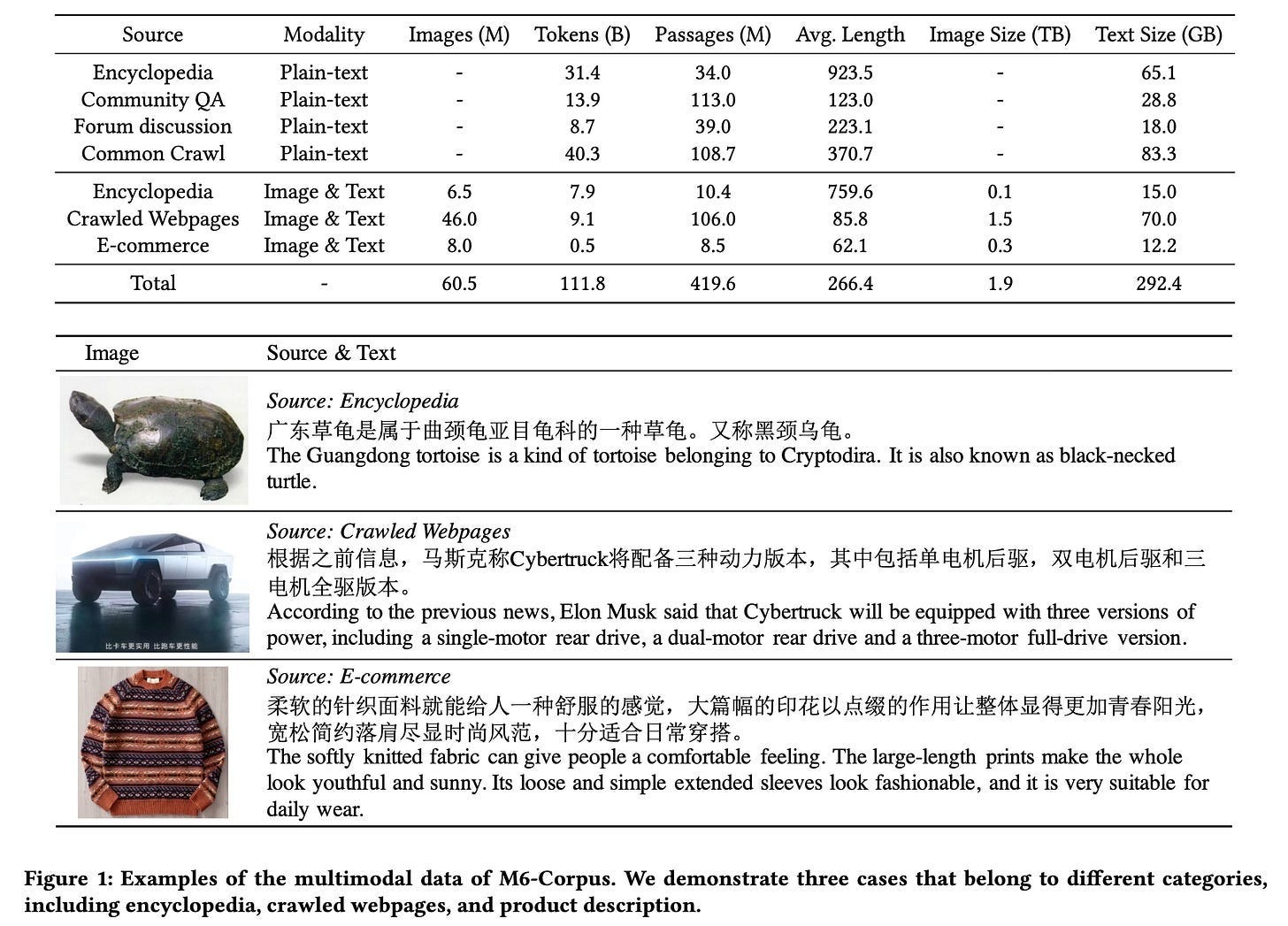
M6 wasn’t DAMO’s only shot. Damo’s Machine Intelligence Lab built AliceMind, a suite of language models including PLUG, a 27-billion-parameter encoder-decoder model. AliceMind traced its roots back to StructBERT, an Alibaba’s 2019 model designed to better capture word and sentence order.
But while research advanced, Alibaba as a company was faltering. Between 2021 and 2022, regulators fined it a record 18.2 billion yuan (US$2.8 billion), equal to 4% of its 2019 revenue, as part of China’s Big Tech crackdown. In the year ending March 2022, Alibaba posted its slowest revenue growth ever, and its stock price plunged by more than half.

As the company stumbled, in 2022, DAMO reportedly laid off 30% of its staff and was tasked with achieving break-even. While Alibaba denied the news, its research arm lost some of its heaviest names. Among those who left were Associate Dean Jin Rong, who was also the dean of iDST; NLP chief Si Luo, who led the AliceMind and StructBERT projects; the head of the City Brain project; the XR Lab lead; and the autonomous driving chief. Yang Hongxia, the mastermind behind M6, soon decamped to ByteDance. It was the first wave of an exodus that would hollow out DAMO’s leadership.
Into the vacuum stepped Zhou Jingren. He was promoted to Alibaba Cloud CTO and quickly set up Tongyi Lab, which consolidated DAMO’s surviving NLP teams (the lab was built between 2022 and 2023 but unfortunately I couldn’t find any public information to locate the specific time).

This move was pivotal—one AI expert friend even described it as Alibaba’s own “Google DeepMind moment,” referring to when, in 2023, Google merged DeepMind with its Brain team into a single, focused unit called Google DeepMind.
By 2022, Alibaba rebranded its NLP models under the “Tongyi” umbrella: a foundation of general-purpose model like M6 and AliceMind, and a growing set of industry-specific models. That same year, it also launched ModelScope, an open-source platform akin to Hugging Face that offers a wide range of pre-trained AI models and tools.
Together, these moves laid the groundwork for Alibaba’s future open-source LLM initiatives.
2. Racing to be China’s First ChatGPT
The ground shifted in December 2022, when OpenAI’s ChatGPT transformed from a unassuming lab project into a viral sensation. Within weeks, millions of people were using a chatbot that felt like science fiction.
Alibaba had M6, later upgraded into M6-OFA, which unifies a diverse set of cross-modal and unimodal tasks, but neither came close to GPT-3.5, the model behind ChatGPT.
Inside China’s AI community, the success of ChatGPT ended a lingering debate. For years, Chinese academics had favored BERT-style bidirectional models, which were believed to offer superior language understanding. However, GPT’s unidirectional decoder-only architecture was able to scale the model’s size at an unprecedented level.
When ChatGPT arrived, Alibaba researchers realized they had bet on the wrong horse. M6’s encoder-decoder architecture was powerful but not built for the kind of smooth, open-domain dialogue that GPT excelled.
Still, by April 2023—six months after ChatGPT’s debut—Alibaba had its own answer. The company unveiled Tongyi Qianwen (通义千问, Qwen is short for Qianwen), a ChatGPT-like chatbot created by Zhou’s Tongyi Lab, at the Alibaba Cloud Summit. Alibaba Chairman Daniel Zhang took the stage to announce that every product in the “Alibaba family” would eventually plug into it. Positioned as a multimodal chatbot, Tongyi Qianwen could generate copy, answer questions, summarize text, write code, and process images and video.

However, unlike rivals Moonshot AI’s Kimi and ByteDance’s Doubao, which aggressively marketed themselves, Tongyi Qianwen grew quiet. There were a few features of Tongyi Qianwen that went viral on Chinese social media, such as making Terracotta Warriors dancing. But the buzz fizzled, and so did the app.
The chatbot was positioned as a window dressing for Alibaba’s AI push. Tongyi Qianwen was packaged alongside Alibaba Cloud’s services to “flex muscle,” rather than positioned as a serious consumer play.
Departments across the company were also unimpressed. According to The Information, many units built their own models or leaned on outside providers. Alimama, Alibaba International, and Ant Group all developed separate LLMs.
Part of the problem was structural. In early 2023, Alibaba unveiled its “1+6+N” restructuring, transforming the company from a centralized company into a federation of businesses. The “1” refers to Alibaba Group as the holding company, while the “6” covers its six core units—Cloud Intelligence, Taobao Tmall Commerce, Local Services, Cainiao Logistics, Global Digital Commerce, and Digital Media & Entertainment—each with its own CEO, board, and IPO potential. The “N” represents smaller, emerging initiatives with greater autonomy. After Alibaba’s “1+6” reorganization, business units had more autonomy—and less incentive to rely on central infrastructure.
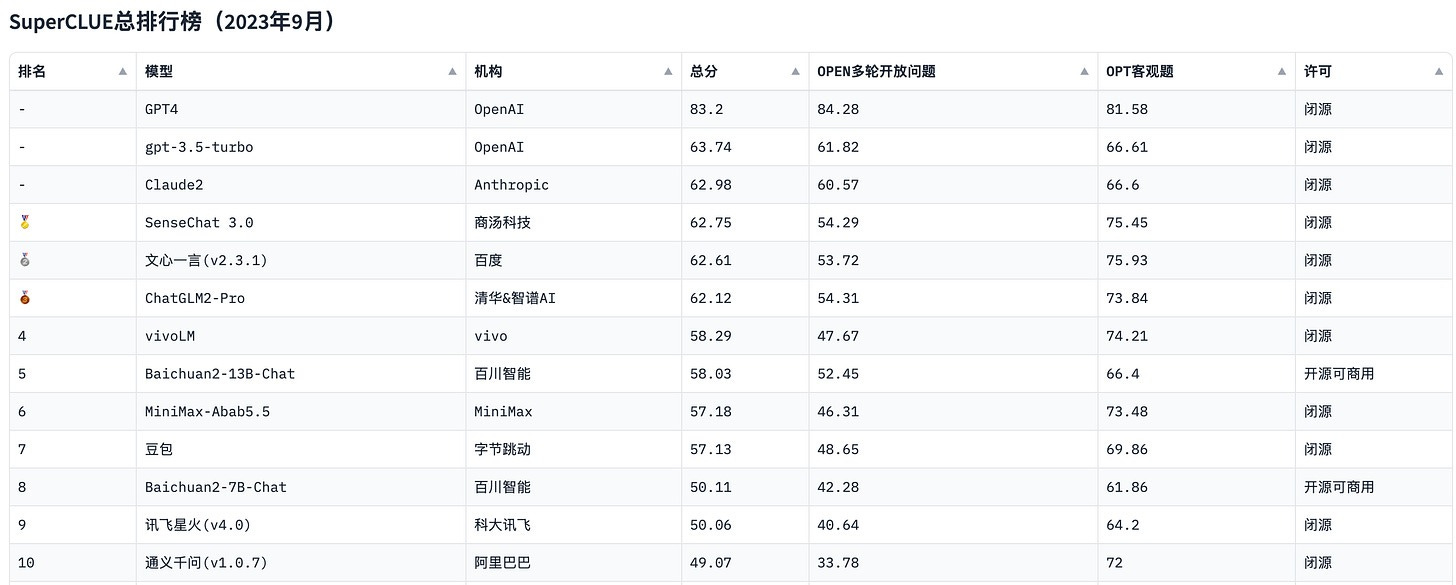
Moreover, the model was far from a leader in 2023. On SuperCLUE, China’s benchmark for evaluating LLMs, Tongyi Qianwen failed to rank among the top eight at any point between May and August of that year, until Alibaba released Tongyi Qianwen 2.0 in October. An AI expert once told me in 2023 that he was worried Alibaba might be falling behind in China’s LLM race.
Even Alibaba itself seemed hesitant to bet on its homegrown technology. Instead, it turned to investment.
3. FOMO Investment
In early 2023, the release of ChatGPT set off a chain reaction in China. Entrepreneurs rushed to stake their claims in generative AI: Yang Zhilin founded Moonshot, Wang Xiaochuan launched Baichuan.ai, and earlier arrivals like MiniMax and Zhipu AI—both born around 2021—pivoted hard into the chatbot race. Within months, they had rolled out large language models, introduced chat products, and raised hundreds of millions of dollars. The press dubbed them China’s “four little AI tigers.”
The force that turned those startups into unicorns was Alibaba. In September 2023, the company appointed its co-founder and former CFO Joe Tsai—the genius dealmaker and financial architect behind Alibaba’s rise—as the chairman. Since then, the company has opened its checkbook.
In October, 2023, Baichuan raised $300 million from Alibaba, Tencent, and Xiaomi.
That same month, Zhipu AI landed 2.5 billion yuan (about $350 million) with Alibaba and Tencent at the table.
In February 2024, Alibaba led a $1 billion round for Moonshot, pushing its valuation to $2.5 billion; a few months later, in its annual report, the company disclosed that it had taken a 36% stake worth about $800 million.
By March, MiniMax had secured $600 million led by Alibaba, valuing the startup at roughly $2.5 billion.
In July, Alibaba joined a $691 million round that pushed MiniMax’s valuation closer to $3 billion.
The playbook looked familiar. Microsoft had supercharged OpenAI with billions in cash and cloud GPU resources, thus resulting in tangible revenue growth in Azure cloud. Alibaba, with its own cloud, could do the same for Chinese startups, pouring capital into AI labs, then funneling their training workloads onto Alibaba Cloud. In the process, it juiced demand for GPUs and secured a seat at the table of whichever startup might eventually dominate the market. By investing in all four, Alibaba didn’t need to pick a winner; it became the house.
Alibaba wasn’t just betting on LLM builders. In March 2025, Manus AI announced a strategic tie-up with the team behind Alibaba’s own Qwen models. Two months later, Alibaba subscribed to $250 million in convertible bonds issued by Meitu, a social-media company moving aggressively into AI-powered agents.
However then, just as quickly, the investment stopped. After mid-2024, Alibaba made no new investments in China’s LLM companies. The reason was simple: its own models had started to gain traction.
4. Open-source Qwen
When Tongyi Qianwen was first introduced, it was a closed-source model. But in August 2023, Alibaba pulled off a surprise: it open-sourced key models from the Tongyi Qianwen family and named Qwen. Qwen-7B, a 7-billion-parameter model, and its chat-tuned version were released under a permissive license for both research and commercial use.
The move was triggered in part by Meta’s release of Llama 2 a month earlier. Llama 2 lowered the barriers for rivals to follow, but it struggled in Chinese. That left an open space in the domestic market—a gap Alibaba stepped in to fill. A Chinese tech giant making its models free to download, fine-tune, and even commercialize was a rare move. Most peers such as ByteDance and Tencent were still guarding their systems behind APIs like OpenAI.
Alibaba open-sourced its models for strategic reasons, not altruism. As Tsai later explained, by open-sourcing core models, Alibaba expects that usage—training, inference, deployments—will increase, which in turn will drive demand for its cloud services and infrastructure. In other words, free models help build a market and ecosystem that they can monetize via cloud computing
At the center of Alibaba’s Qwen open-source push is Lin Junyang, a 32-year-old research fellow who also developed M6 and Tongyi Qianwen. Unlike most AI scientists, who come from computer science or engineering, Lin studied linguistics. He earned a bachelor’s in Linguistics and Applied Linguistics at Peking University.

Within six weeks, Alibaba followed with Qwen-14B and a technical report—the first Chinese company to publish such detailed documentation. Despite its modest size, Qwen-7B topped Hugging Face’s Open LLM Leaderboard among models under 10B parameters. By late August, the company added Qwen-VL, a multimodal model capable of handling both text and images, flexing muscles similar to OpenAI’s own vision-enabled systems.
From there, the cadence quickened. December 2023 brought Qwen-72B and Qwen-1.8B, a high-end and low-end pair, plus models for speech understanding. By 2024, the Qwen family spanned natural language, vision, and audio—one of the most comprehensive open models in the world.
In June 2024, Alibaba launched Qwen2, with the flagship 72B model posting SOTA results on 15 benchmarks. Three months later came Qwen2.5, more than 100 models from 0.5B to 72B parameters, stronger coding and math skills, and support for 29 languages. That was the genuinely the first time Qwen series gained traction in both Chinese and U.S. communities.
In the meantime, Alibaba Cloud ramped up efforts to persuade other business units to adopt its Qwen models across all AI products. Employees reached out to teams developing AI features, trying to forge closer ties.
While Alibaba still focused on both proprietary and open-source versions of Qwen, throughout 2024, the balance shifted. As the open-source models began drawing steady feedback from developers in China and the U.S., startups, academic researchers, and PhD students started using them to build custom AI systems. That momentum gradually pushed Alibaba’s emphasis toward open source.
By late 2024, China’s AI war had narrowed to two giants: Alibaba and ByteDance. ByteDance’s models were closing the performance gap, and its chatbot climbed to the top of app download charts. Alibaba, meanwhile, was gaining momentum—its Qwen models won over developers, its cloud arm surged in the enterprise market, and a spree of early-year investments brought fresh allies.
The contest turned personal when ByteDance poached Zhou Chang, the tech lead behind Qwen. Alibaba hit back with an arbitration case, accusing him of breaking non-compete and non-solicitation clauses.
5. Qwen vs DeepSeek
By late 2024, OpenAI released o1 models and unveiled a new paradigm called time-inference compute—by extending inference compute to improve the model’s reasoning ability through a technology called reinforcement learning.
Quickly following up, Alibaba said in November that they were experimenting with a similar specialized reasoning model called QwQ.
But before it was released, the company was blindsided. DeepSeek, a then little-known Chinese startup backed by quant-trading powerhouse High-Flyer, dropped R1, an open-source reasoning model that rivaled OpenAI’s o1. Later, the methodology used to train DeepSeek-R1 was published in Nature.

The launch was a sensation, quickly catapulting DeepSeek into the role of China’s AI standard-bearer. Developers flocked to R1, enterprises began embedding it in apps, and even Alibaba’s own travel arm, Feizhu, announced integrations. A year of Alibaba’s quiet community-building seemed at risk of being erased overnight.
“We read the research papers and we said, ‘Holy cow, how come we have fallen behind? We were doing the same things,’” said Tsai at Viva Tech 2025 in Paris this June.
“What happened was our engineering lead decided and said, ‘Cancel your Chinese New Year holiday, everybody stay in the company, sleep in the office, we’re gonna accelerate our development.’”
Under pressure, Alibaba’s AI division refused to fold. On the first day of the Chinese New Year—where everyone in China was supposed to rest and unite with their families—the company released Qwen2.5 Max, its latest-gen LLM that outperforms DeepSeek-V3.
Three months later came Qwen3, its most ambitious LLM yet. Jack Ma, six years into retirement, was demanding regular progress reports from Zhou Jingren—a sign of how strategically important Qwen had become. The series spanned from 0.6B to 235B parameters, used an efficient Mixture-of-Experts design, and pushed hybrid reasoning into mainstream use. It excelled in math, coding, and multilingual reasoning across 119 languages, handled context windows of up to 128,000 tokens, and—critically—was released under the Apache 2.0 license.

By mid-2025, the Qwen family had been downloaded more than 400 million times, with over 140,000 derivative models built on top, cementing Alibaba’s place at the center of open-source AI.
As Qwen gained momentum, Alibaba’s scientists themselves became hot targets in China’s intensifying AI talent wars. In January, Yan Zhijie, an early member of DAMO Academy and former head of Tongyi’s speech lab, joined JD.com’s Explore Academy. Not long after, Bo Liefeng, who once ran Tongyi’s applied vision division, defected to Tencent’s Hunyuan AI team. Added to the earlier exit of Zhou Chang, the top leads of Tongyi’s three core labs—language, speech, and vision—were gone. It marked Alibaba’s second major brain drain since the mass departure at DAMO in 2022. China’s AI talent wars, it turned out, were no less ruthless than Silicon Valley’s.
Yet Alibaba still has gravitational pull. Early this year, it announced a joint lab with 01.AI, the startup founded by Kai-Fu Lee, after Lee abandoned efforts to train his own LLMs. Several of 01.AI’s core researchers have since joined Alibaba.
As Lee put it, “In the end, China’s AI market may only have three major model companies left: DeepSeek, Alibaba, and ByteDance.”
6. Playing Long Game
In February 2025, at the World Governments Summit in Dubai, chairman Tsai announced that Apple had chosen Alibaba as its partner for Apple Intelligence in China. The win turbocharged Alibaba’s AI credentials.
The wins extended to the balance sheet. In the second quarter of 2025, Alibaba Cloud’s revenue grew 26 percent YoY, with AI sales notching a seventh consecutive quarter of triple-digit growth. Consumer-facing apps also showed unexpected strength. Quark, once a niche search-and-cloud drive app, was morphing into a full-blown AI super app that won youngsters’ favor.
Then came the number investors craved: ¥380 billion ($53 billion). That’s the amount CEO Eddie Wu pledged to spend over three years on cloud and AI infrastructure—more than the company had invested in the previous decade combined. The announcement sent Alibaba’s U.S. shares soaring more than 11 percent in minutes.
Wu’s speech at the 2025 Apsara conference reinforced their strategic bets, that first, LLMs will become the next operating system, with natural language as the programming language and agents as the new software—which is why they’ve chosen to open-source Qwen as the “Android of AI” to build a massive developer ecosystem.
Second, they believe only 5-6 “super AI clouds” will survive to handle the massive computational demands of the future AI world. In their envisioned “Artificial Super Intelligence Era”, every person might use 100 GPU chips worth of AI power, with agents and robots working 24/7 to amplify human intelligence by 10x or 100x. If AI becomes as fundamental as electricity, Alibaba Cloud will serve as both the generator and the grid for this new form of digital power.
Alibaba also laid out their Qwen roadmap, which represents a brute-force scaling strategy that pushes every technical boundary simultaneously:
Expanding context length from 1 million to 10 million and 100 million tokens,
Scaling parameters from trillion to ten trillion
Increasing test-time compute by 15x to 1 million
Training on 100 trillion tokens—ten times their current data scale.
Doubling down on synthetic data generation “without scale limits”
Building more sophisticated agents across complexity, interaction, and learning capabilities.
Alibaba is also using its own AI chips to train LLMs—a move that would echo Google’s TPU play and tighten control over its stack. The company’s chip division T-Head’s AI accelerator, codenamed PPU, is meant to rival Nvidia’s H20, and it has already landed a major deployment with China Unicom at its Sanjiangyuan Big Data Base in Qinghai.

Yet the value of the AI push may lie elsewhere. More than revenue or partnerships, AI has restored belief inside Alibaba. For a company experiencing tech crackdown and fierce competitions, AI has given employees—and investors—a new hope: that Alibaba can be, and will be, great again.
In the end, that morale boost is more valuable than any benchmark score.
really excellent piece Tony!